Microsoft DP-200 Exam Practice Questions (P. 2)
- Full Access (372 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #13
DRAG DROP -
You manage a financial computation data analysis process. Microsoft Azure virtual machines (VMs) run the process in daily jobs, and store the results in virtual hard drives (VHDs.)
The VMs product results using data from the previous day and store the results in a snapshot of the VHD. When a new month begins, a process creates a new
VHD.
You must implement the following data retention requirements:
✑ Daily results must be kept for 90 days
✑ Data for the current year must be available for weekly reports
✑ Data from the previous 10 years must be stored for auditing purposes
✑ Data required for an audit must be produced within 10 days of a request.
You need to enforce the data retention requirements while minimizing cost.
How should you configure the lifecycle policy? To answer, drag the appropriate JSON segments to the correct locations. Each JSON segment may be used once, more than once, or not at all. You may need to drag the split bat between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

You manage a financial computation data analysis process. Microsoft Azure virtual machines (VMs) run the process in daily jobs, and store the results in virtual hard drives (VHDs.)
The VMs product results using data from the previous day and store the results in a snapshot of the VHD. When a new month begins, a process creates a new
VHD.
You must implement the following data retention requirements:
✑ Daily results must be kept for 90 days
✑ Data for the current year must be available for weekly reports
✑ Data from the previous 10 years must be stored for auditing purposes
✑ Data required for an audit must be produced within 10 days of a request.
You need to enforce the data retention requirements while minimizing cost.
How should you configure the lifecycle policy? To answer, drag the appropriate JSON segments to the correct locations. Each JSON segment may be used once, more than once, or not at all. You may need to drag the split bat between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:

The Set-AzStorageAccountManagementPolicy cmdlet creates or modifies the management policy of an Azure Storage account.
Example: Create or update the management policy of a Storage account with ManagementPolicy rule objects.

Action -BaseBlobAction Delete -daysAfterModificationGreaterThan 100
PS C:\>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -BaseBlobAction TierToArchive -daysAfterModificationGreaterThan 50
PS C:\>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -BaseBlobAction TierToCool -daysAfterModificationGreaterThan 30
PS C:\>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -SnapshotAction Delete -daysAfterCreationGreaterThan 100
PS C:\>$filter1 = New-AzStorageAccountManagementPolicyFilter -PrefixMatch ab,cd
PS C:\>$rule1 = New-AzStorageAccountManagementPolicyRule -Name Test -Action $action1 -Filter $filter1
PS C:\>$action2 = Add-AzStorageAccountManagementPolicyAction -BaseBlobAction Delete -daysAfterModificationGreaterThan 100
PS C:\>$filter2 = New-AzStorageAccountManagementPolicyFilter
References:
https://docs.microsoft.com/en-us/powershell/module/az.storage/set-azstorageaccountmanagementpolicy
The Set-AzStorageAccountManagementPolicy cmdlet creates or modifies the management policy of an Azure Storage account.
Example: Create or update the management policy of a Storage account with ManagementPolicy rule objects.
Action -BaseBlobAction Delete -daysAfterModificationGreaterThan 100
PS C:\>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -BaseBlobAction TierToArchive -daysAfterModificationGreaterThan 50
PS C:\>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -BaseBlobAction TierToCool -daysAfterModificationGreaterThan 30
PS C:\>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -SnapshotAction Delete -daysAfterCreationGreaterThan 100
PS C:\>$filter1 = New-AzStorageAccountManagementPolicyFilter -PrefixMatch ab,cd
PS C:\>$rule1 = New-AzStorageAccountManagementPolicyRule -Name Test -Action $action1 -Filter $filter1
PS C:\>$action2 = Add-AzStorageAccountManagementPolicyAction -BaseBlobAction Delete -daysAfterModificationGreaterThan 100
PS C:\>$filter2 = New-AzStorageAccountManagementPolicyFilter
References:
https://docs.microsoft.com/en-us/powershell/module/az.storage/set-azstorageaccountmanagementpolicy
Question #14
A company plans to use Azure SQL Database to support a mission-critical application.
The application must be highly available without performance degradation during maintenance windows.
You need to implement the solution.
Which three technologies should you implement? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
The application must be highly available without performance degradation during maintenance windows.
You need to implement the solution.
Which three technologies should you implement? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- APremium service tier
- BVirtual machine Scale Sets
- CBasic service tier
- DSQL Data Sync
- EAlways On availability groups
- FZone-redundant configuration
Correct Answer:
AEF
A: Premium/business critical service tier model that is based on a cluster of database engine processes. This architectural model relies on a fact that there is always a quorum of available database engine nodes and has minimal performance impact on your workload even during maintenance activities.
E: In the premium model, Azure SQL database integrates compute and storage on the single node. High availability in this architectural model is achieved by replication of compute (SQL Server Database Engine process) and storage (locally attached SSD) deployed in 4-node cluster, using technology similar to SQL
Server Always On Availability Groups.
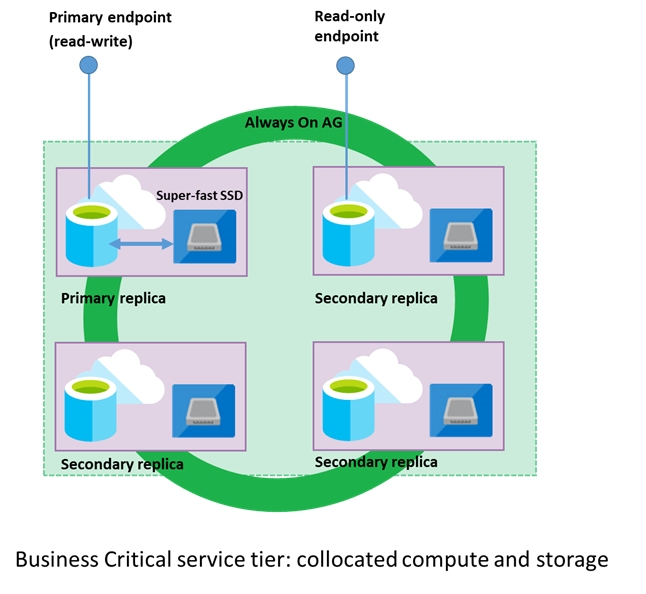
F: Zone redundant configuration -
By default, the quorum-set replicas for the local storage configurations are created in the same datacenter. With the introduction of Azure Availability Zones, you have the ability to place the different replicas in the quorum-sets to different availability zones in the same region. To eliminate a single point of failure, the control ring is also duplicated across multiple zones as three gateway rings (GW).
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-high-availability
AEF
A: Premium/business critical service tier model that is based on a cluster of database engine processes. This architectural model relies on a fact that there is always a quorum of available database engine nodes and has minimal performance impact on your workload even during maintenance activities.
E: In the premium model, Azure SQL database integrates compute and storage on the single node. High availability in this architectural model is achieved by replication of compute (SQL Server Database Engine process) and storage (locally attached SSD) deployed in 4-node cluster, using technology similar to SQL
Server Always On Availability Groups.
F: Zone redundant configuration -
By default, the quorum-set replicas for the local storage configurations are created in the same datacenter. With the introduction of Azure Availability Zones, you have the ability to place the different replicas in the quorum-sets to different availability zones in the same region. To eliminate a single point of failure, the control ring is also duplicated across multiple zones as three gateway rings (GW).
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-high-availability
Question #16
DRAG DROP -
You are developing a solution to visualize multiple terabytes of geospatial data.
The solution has the following requirements:
✑ Data must be encrypted.
✑ Data must be accessible by multiple resources on Microsoft Azure.
You need to provision storage for the solution.
Which four actions should you perform in sequence? To answer, move the appropriate action from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
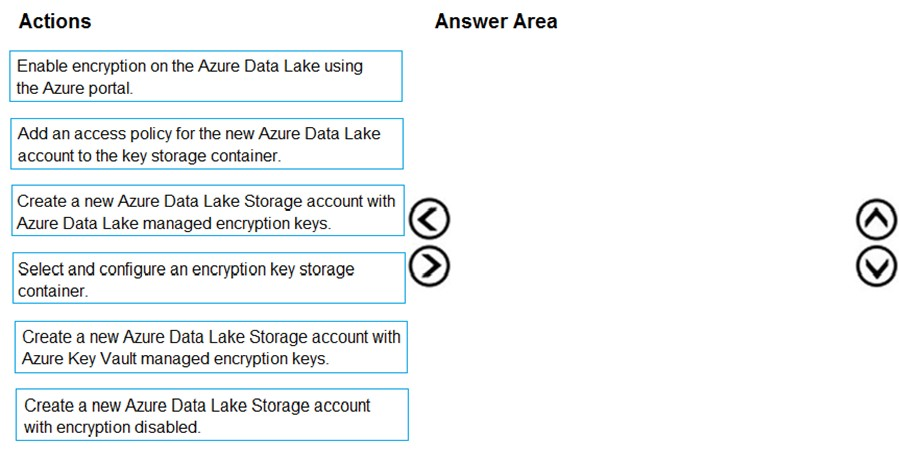
You are developing a solution to visualize multiple terabytes of geospatial data.
The solution has the following requirements:
✑ Data must be encrypted.
✑ Data must be accessible by multiple resources on Microsoft Azure.
You need to provision storage for the solution.
Which four actions should you perform in sequence? To answer, move the appropriate action from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
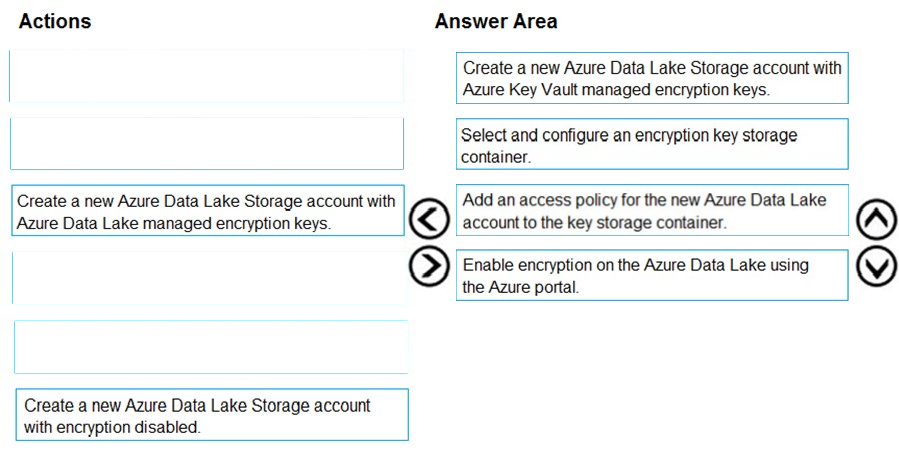
Create a new Azure Data Lake Storage account with Azure Data Lake managed encryption keys
For Azure services, Azure Key Vault is the recommended key storage solution and provides a common management experience across services. Keys are stored and managed in key vaults, and access to a key vault can be given to users or services. Azure Key Vault supports customer creation of keys or import of customer keys for use in customer-managed encryption key scenarios.
Note: Data Lake Storage Gen1 account Encryption Settings. There are three options:
✑ Do not enable encryption.
✑ Use keys managed by Data Lake Storage Gen1, if you want Data Lake Storage Gen1 to manage your encryption keys.
✑ Use keys from your own Key Vault. You can select an existing Azure Key Vault or create a new Key Vault. To use the keys from a Key Vault, you must assign permissions for the Data Lake Storage Gen1 account to access the Azure Key Vault.
References:
https://docs.microsoft.com/en-us/azure/security/fundamentals/encryption-atrest
Create a new Azure Data Lake Storage account with Azure Data Lake managed encryption keys
For Azure services, Azure Key Vault is the recommended key storage solution and provides a common management experience across services. Keys are stored and managed in key vaults, and access to a key vault can be given to users or services. Azure Key Vault supports customer creation of keys or import of customer keys for use in customer-managed encryption key scenarios.
Note: Data Lake Storage Gen1 account Encryption Settings. There are three options:
✑ Do not enable encryption.
✑ Use keys managed by Data Lake Storage Gen1, if you want Data Lake Storage Gen1 to manage your encryption keys.
✑ Use keys from your own Key Vault. You can select an existing Azure Key Vault or create a new Key Vault. To use the keys from a Key Vault, you must assign permissions for the Data Lake Storage Gen1 account to access the Azure Key Vault.
References:
https://docs.microsoft.com/en-us/azure/security/fundamentals/encryption-atrest
Question #19
HOTSPOT -
You are developing a solution using a Lambda architecture on Microsoft Azure.
The data at rest layer must meet the following requirements:
Data storage:
✑ Serve as a repository for high volumes of large files in various formats.
✑ Implement optimized storage for big data analytics workloads.
✑ Ensure that data can be organized using a hierarchical structure.
Batch processing:
✑ Use a managed solution for in-memory computation processing.
✑ Natively support Scala, Python, and R programming languages.
✑ Provide the ability to resize and terminate the cluster automatically.
Analytical data store:
✑ Support parallel processing.
✑ Use columnar storage.
✑ Support SQL-based languages.
You need to identify the correct technologies to build the Lambda architecture.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You are developing a solution using a Lambda architecture on Microsoft Azure.
The data at rest layer must meet the following requirements:
Data storage:
✑ Serve as a repository for high volumes of large files in various formats.
✑ Implement optimized storage for big data analytics workloads.
✑ Ensure that data can be organized using a hierarchical structure.
Batch processing:
✑ Use a managed solution for in-memory computation processing.
✑ Natively support Scala, Python, and R programming languages.
✑ Provide the ability to resize and terminate the cluster automatically.
Analytical data store:
✑ Support parallel processing.
✑ Use columnar storage.
✑ Support SQL-based languages.
You need to identify the correct technologies to build the Lambda architecture.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
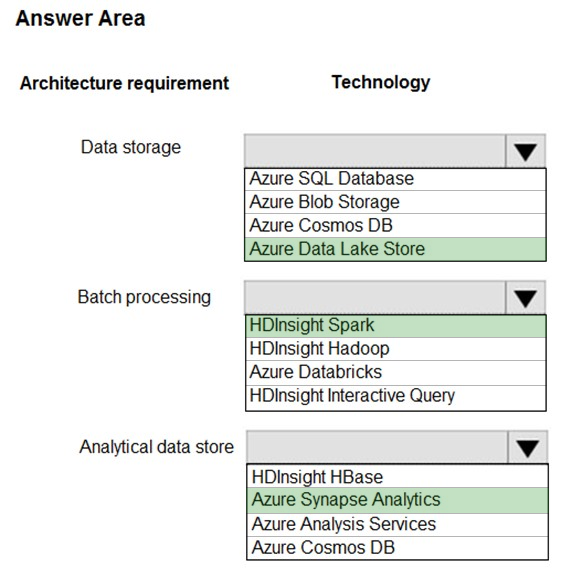
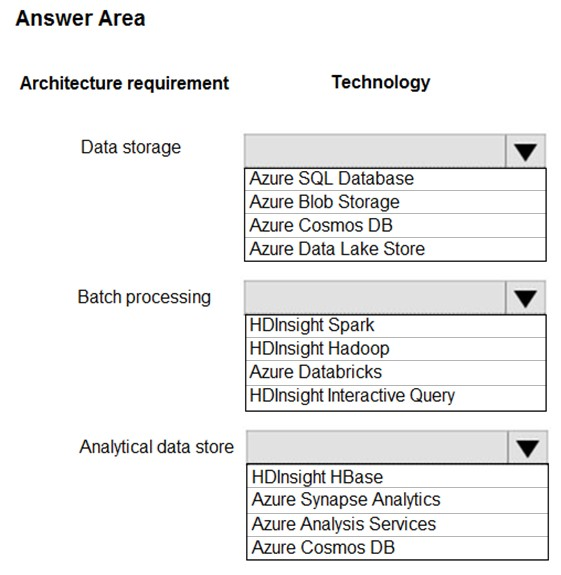
Data storage: Azure Data Lake Store
A key mechanism that allows Azure Data Lake Storage Gen2 to provide file system performance at object storage scale and prices is the addition of a hierarchical namespace. This allows the collection of objects/files within an account to be organized into a hierarchy of directories and nested subdirectories in the same way that the file system on your computer is organized. With the hierarchical namespace enabled, a storage account becomes capable of providing the scalability and cost-effectiveness of object storage, with file system semantics that are familiar to analytics engines and frameworks.
Batch processing: HD Insight Spark
Aparch Spark is an open-source, parallel-processing framework that supports in-memory processing to boost the performance of big-data analysis applications.
HDInsight is a managed Hadoop service. Use it deploy and manage Hadoop clusters in Azure. For batch processing, you can use Spark, Hive, Hive LLAP,
MapReduce.
Languages: R, Python, Java, Scala, SQL
Analytic data store: Azure Synapse Analytics
Azure Synapse Analytics Warehouse is a cloud-based Enterprise Data Warehouse (EDW) that uses Massively Parallel Processing (MPP).
Azure Synapse Analytics stores data into relational tables with columnar storage.
Note: As of November 2019, Azure SQL Data Warehouse is now Azure Synapse Analytics.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-namespace https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-overview-what-is
Data storage: Azure Data Lake Store
A key mechanism that allows Azure Data Lake Storage Gen2 to provide file system performance at object storage scale and prices is the addition of a hierarchical namespace. This allows the collection of objects/files within an account to be organized into a hierarchy of directories and nested subdirectories in the same way that the file system on your computer is organized. With the hierarchical namespace enabled, a storage account becomes capable of providing the scalability and cost-effectiveness of object storage, with file system semantics that are familiar to analytics engines and frameworks.
Batch processing: HD Insight Spark
Aparch Spark is an open-source, parallel-processing framework that supports in-memory processing to boost the performance of big-data analysis applications.
HDInsight is a managed Hadoop service. Use it deploy and manage Hadoop clusters in Azure. For batch processing, you can use Spark, Hive, Hive LLAP,
MapReduce.
Languages: R, Python, Java, Scala, SQL
Analytic data store: Azure Synapse Analytics
Azure Synapse Analytics Warehouse is a cloud-based Enterprise Data Warehouse (EDW) that uses Massively Parallel Processing (MPP).
Azure Synapse Analytics stores data into relational tables with columnar storage.
Note: As of November 2019, Azure SQL Data Warehouse is now Azure Synapse Analytics.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-namespace https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-overview-what-is
Question #20
DRAG DROP -
Your company has an on-premises Microsoft SQL Server instance.
The data engineering team plans to implement a process that copies data from the SQL Server instance to Azure Blob storage once a day. The process must orchestrate and manage the data lifecycle.
You need to create Azure Data Factory to connect to the SQL Server instance.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Your company has an on-premises Microsoft SQL Server instance.
The data engineering team plans to implement a process that copies data from the SQL Server instance to Azure Blob storage once a day. The process must orchestrate and manage the data lifecycle.
You need to create Azure Data Factory to connect to the SQL Server instance.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
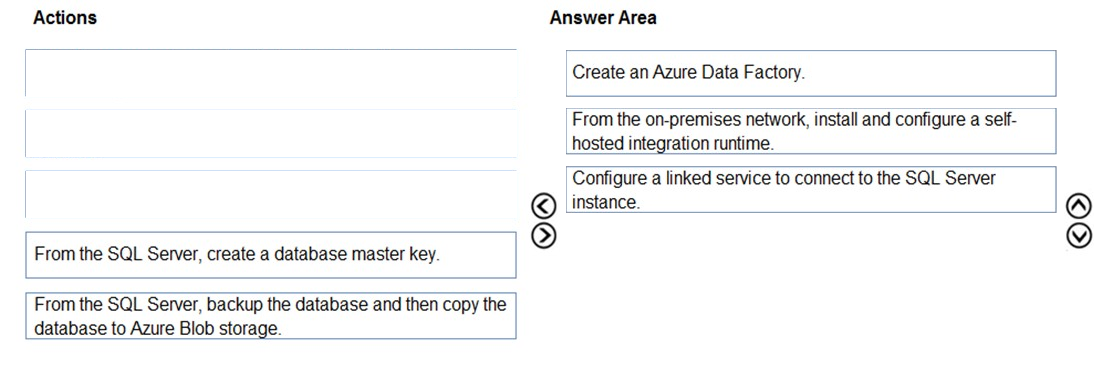
Step 1: Create an Azure Data Factory
You need to create a data factory and start the Data Factory UI to create a pipeline in the data factory.
Step 2: From the on-premises network, install and configure a self-hosted runtime.
To use copy data from a SQL Server database that isn't publicly accessible, you need to set up a self-hosted integration runtime.
Step 3: Configure a linked service to connect to the SQL Server instance.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/connector-sql-server https://www.mssqltips.com/sqlservertip/5812/connect-to-onpremises-data-in-azure-data-factory-with-the-selfhosted-integration-runtime--part-1/
Step 1: Create an Azure Data Factory
You need to create a data factory and start the Data Factory UI to create a pipeline in the data factory.
Step 2: From the on-premises network, install and configure a self-hosted runtime.
To use copy data from a SQL Server database that isn't publicly accessible, you need to set up a self-hosted integration runtime.
Step 3: Configure a linked service to connect to the SQL Server instance.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/connector-sql-server https://www.mssqltips.com/sqlservertip/5812/connect-to-onpremises-data-in-azure-data-factory-with-the-selfhosted-integration-runtime--part-1/
All Pages