Microsoft 70-776 Exam Practice Questions (P. 5)
- Full Access (83 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #21
DRAG DROP -
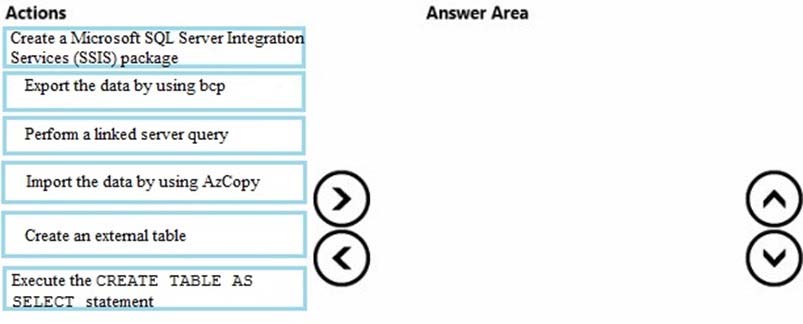
You have eight tab-delimited text files. Each file has 100 GB of order history data that is separated by year and by month. The files are stored on a Microsoft Azure virtual machine that has eight processor cores. Each file is stored on a separate SSD drive on the virtual machine. There is a dedicated controller for each drive.
You define a table in Azure SQL Data Warehouse that is partitioned by year and by month, and has a clustered index.
You need to load the data from the files to Azure SQL Data Warehouse. The solution must minimize load times and must use multiple compute nodes simultaneously.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
You have eight tab-delimited text files. Each file has 100 GB of order history data that is separated by year and by month. The files are stored on a Microsoft Azure virtual machine that has eight processor cores. Each file is stored on a separate SSD drive on the virtual machine. There is a dedicated controller for each drive.
You define a table in Azure SQL Data Warehouse that is partitioned by year and by month, and has a clustered index.
You need to load the data from the files to Azure SQL Data Warehouse. The solution must minimize load times and must use multiple compute nodes simultaneously.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
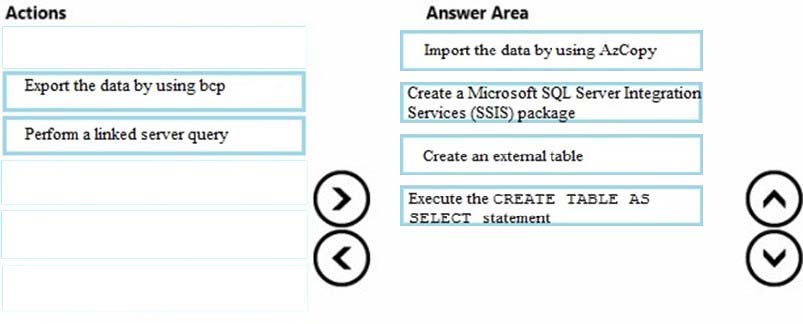
Although there are many variations for implementing ELT for SQL Data Warehouse, these are the basic steps:
1. Extract the source data into text files.
2. Land the data into Azure Blob storage or Azure Data Lake Store.
3. Prepare the data for loading.
4. Load the data into SQL Data Warehouse staging tables by using PolyBase.
5. Transform the data.
6. Insert the data into production tables.
Step 1:
AZCopy utility moves data to Azure Storage over the public internet. This works if your data sizes are less than 10 TB.
Step 2:
You might need to prepare and clean the data in your storage account before loading it into SQL Data Warehouse. Data preparation can be performed while your data is in the source, as you export the data to text files, or after the data is in Azure Storage. It is easiest to work with the data as early in the process as possible.
Step 3:
Before you can load data, you need to define external tables in your data warehouse. PolyBase uses external tables to define and access the data in Azure
Storage. The external table is similar to a regular table. The main difference is the external table points to data that is stored outside the data warehouse.
Step 4:
Load to a staging table -
To get data into the data warehouse, it works well to first load the data into a staging table. By using a staging table, you can handle errors without interfering with the production tables, and you avoid running rollback operations on the production table. A staging table also gives you the opportunity to use SQL Data
Warehouse to run transformations before inserting the data into production tables.
To load with T-SQL, run the CREATE TABLE AS SELECT (CTAS) T-SQL statement. This command inserts the results of a select statement into a new table.
When the statement selects from an external table, it imports the external data.
Incorrect Answers:
BCP:
bcp loads directly to SQL Data Warehouse without going through Azure Blob storage, and is intended only for small loads.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/design-elt-data-loading
Although there are many variations for implementing ELT for SQL Data Warehouse, these are the basic steps:
1. Extract the source data into text files.
2. Land the data into Azure Blob storage or Azure Data Lake Store.
3. Prepare the data for loading.
4. Load the data into SQL Data Warehouse staging tables by using PolyBase.
5. Transform the data.
6. Insert the data into production tables.
Step 1:
AZCopy utility moves data to Azure Storage over the public internet. This works if your data sizes are less than 10 TB.
Step 2:
You might need to prepare and clean the data in your storage account before loading it into SQL Data Warehouse. Data preparation can be performed while your data is in the source, as you export the data to text files, or after the data is in Azure Storage. It is easiest to work with the data as early in the process as possible.
Step 3:
Before you can load data, you need to define external tables in your data warehouse. PolyBase uses external tables to define and access the data in Azure
Storage. The external table is similar to a regular table. The main difference is the external table points to data that is stored outside the data warehouse.
Step 4:
Load to a staging table -
To get data into the data warehouse, it works well to first load the data into a staging table. By using a staging table, you can handle errors without interfering with the production tables, and you avoid running rollback operations on the production table. A staging table also gives you the opportunity to use SQL Data
Warehouse to run transformations before inserting the data into production tables.
To load with T-SQL, run the CREATE TABLE AS SELECT (CTAS) T-SQL statement. This command inserts the results of a select statement into a new table.
When the statement selects from an external table, it imports the external data.
Incorrect Answers:
BCP:
bcp loads directly to SQL Data Warehouse without going through Azure Blob storage, and is intended only for small loads.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/design-elt-data-loading
Question #22
You have a Microsoft Azure SQL data warehouse.
You need to configure Data Warehouse Units (DWUs) to ensure that you have six compute nodes. The solution must minimize costs.
Which value should set for the DWUs?
You need to configure Data Warehouse Units (DWUs) to ensure that you have six compute nodes. The solution must minimize costs.
Which value should set for the DWUs?
- ADW200
- BDW400
- CDW600
- DDW1000
Correct Answer:
C
The following table shows how the number of distributions per Compute node changes as the data warehouse units change. DWU6000 provides 60 Compute nodes and achieves much higher query performance than DWU100.
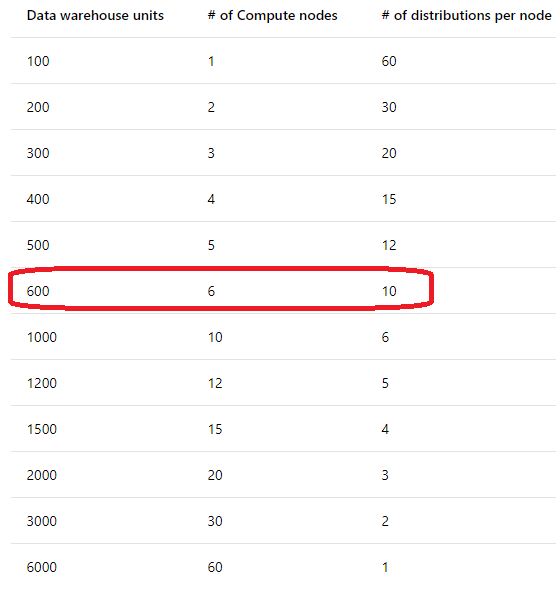
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-manage-compute-overview
C
The following table shows how the number of distributions per Compute node changes as the data warehouse units change. DWU6000 provides 60 Compute nodes and achieves much higher query performance than DWU100.
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-manage-compute-overview
Question #23
You have a fact table named PowerUsage that has 10 billion rows. PowerUsage contains data about customer power usage during the last 12 months. The usage data is collected every minute. PowerUsage contains the columns configured as shown in the following table.
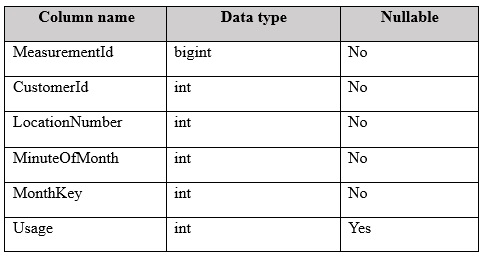
LocationNumber has a default value of 1. The MinuteOfMonth column contains the relative minute within each month. The value resets at the beginning of each month.
A sample of the fact table data is shown in the following table.
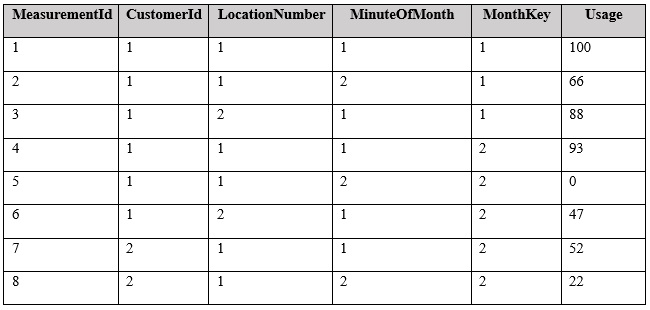
There is a related table named Customer that joins to the PowerUsage table on the CustomerId column. Sixty percent of the rows in PowerUsage are associated to less than 10 percent of the rows in Customer. Most queries do not require the use of the Customer table. Many queries select on a specific month.
You need to minimize how long it takes to find the records for a specific month.
What should you do?
LocationNumber has a default value of 1. The MinuteOfMonth column contains the relative minute within each month. The value resets at the beginning of each month.
A sample of the fact table data is shown in the following table.
There is a related table named Customer that joins to the PowerUsage table on the CustomerId column. Sixty percent of the rows in PowerUsage are associated to less than 10 percent of the rows in Customer. Most queries do not require the use of the Customer table. Many queries select on a specific month.
You need to minimize how long it takes to find the records for a specific month.
What should you do?
Question #24
You have an extract transformation, and load (ETL) process for a Microsoft Azure SQL data warehouse.
You run the following statements to create the logon and user for an account that will run the nightly data load for the data warehouse.
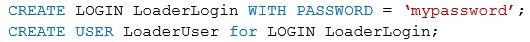
You connect to the data warehouse.
You need to ensure that the user can access the highest resource class.
Which statement should you execute?
You run the following statements to create the logon and user for an account that will run the nightly data load for the data warehouse.
You connect to the data warehouse.
You need to ensure that the user can access the highest resource class.
Which statement should you execute?
- AALTER SERVER ROLE LargeRC ADD MEMBER LoaderUser;
- BEXEC sp_addrolemember "˜largerc', "˜LoaderLogin'
- CALTER SERVER ROLE xLargeRC ADD MEMBER LoaderLogin;
- DEXEC sp_addrolemember "˜xlargerc', "˜LoaderUser'
Correct Answer:
D
Dynamic Resource Classes (smallrc, mediumrc, largerc, xlargerc) allocate a variable amount of memory depending on the current DWU. This means that when you scale up to a larger DWU, your queries automatically get more memory.
Memory allocations per distribution for dynamic resource classes (MB)
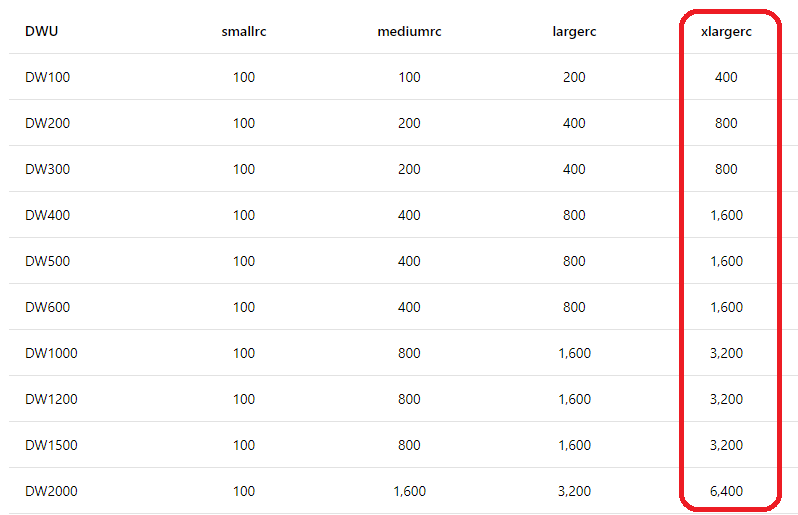
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-develop-concurrency
D
Dynamic Resource Classes (smallrc, mediumrc, largerc, xlargerc) allocate a variable amount of memory depending on the current DWU. This means that when you scale up to a larger DWU, your queries automatically get more memory.
Memory allocations per distribution for dynamic resource classes (MB)
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-develop-concurrency
All Pages