Microsoft 70-776 Exam Practice Questions (P. 2)
- Full Access (83 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #6
Note: This question is part of series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.

You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You change the external attribute to true.
Does this meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.
You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You change the external attribute to true.
Does this meet the goal?
Question #7
DRAG DROP -
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
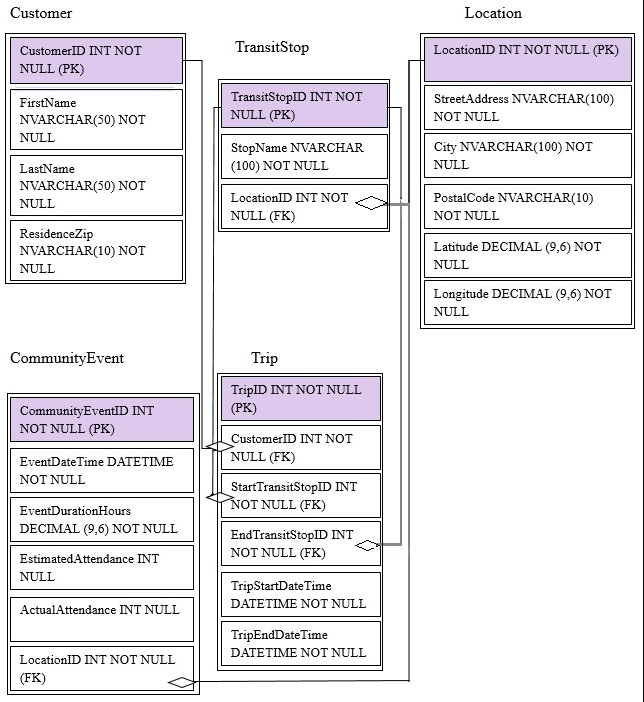
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.

You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
Which types of threat detection should you configure for each threat pattern? To answer, drag the appropriate threat detection types to the correct patterns. Each threat detection type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.
You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
Which types of threat detection should you configure for each threat pattern? To answer, drag the appropriate threat detection types to the correct patterns. Each threat detection type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:

SQL Threat Detection provides a new layer of security, which enables customers to detect and respond to potential threats as they occur by providing security alerts on anomalous activities. Users receive an alert upon suspicious database activities, potential vulnerabilities, and SQL injection attacks, as well as anomalous database access patterns.
From scenario: You plan to detect the following two threat patterns:
Pattern1: A user logs in from two physical locations.
Pattern2: A user attempts to gain elevated permissions.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-threat-detection
SQL Threat Detection provides a new layer of security, which enables customers to detect and respond to potential threats as they occur by providing security alerts on anomalous activities. Users receive an alert upon suspicious database activities, potential vulnerabilities, and SQL injection attacks, as well as anomalous database access patterns.
From scenario: You plan to detect the following two threat patterns:
Pattern1: A user logs in from two physical locations.
Pattern2: A user attempts to gain elevated permissions.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-threat-detection
Question #8
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
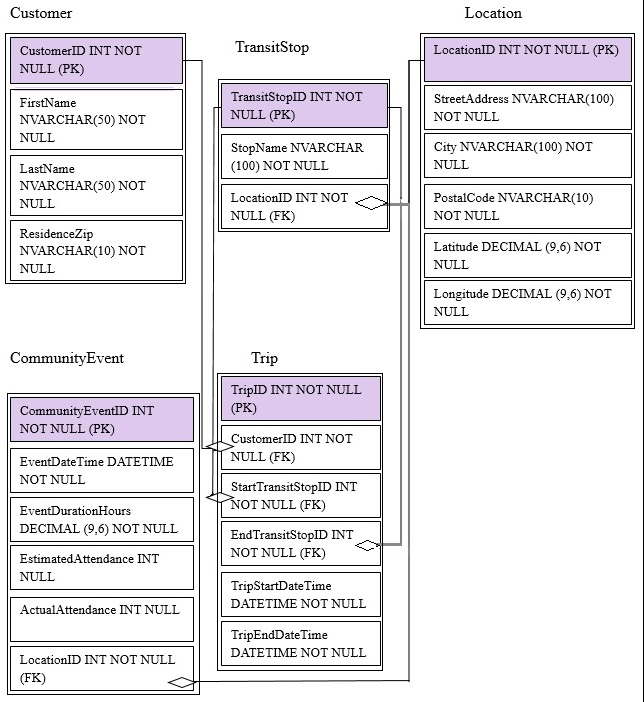
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.

You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
You plan to create the Azure Data Factory pipeline.
Which activity requires that you create a custom activity?
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.
You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
You plan to create the Azure Data Factory pipeline.
Which activity requires that you create a custom activity?
Question #9
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
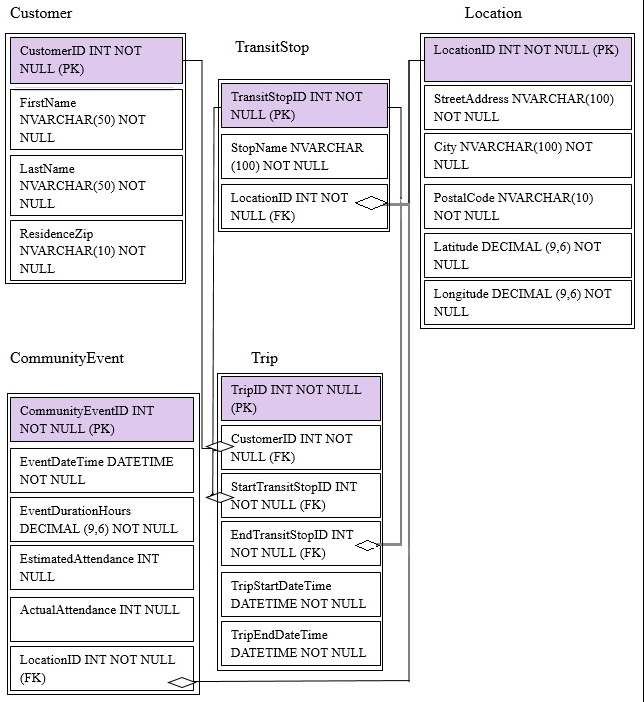
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.

You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
You need to copy the weather data for June 2016 to StorageAccount1.
Which command should you run on AzureVM1?
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.
You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
You need to copy the weather data for June 2016 to StorageAccount1.
Which command should you run on AzureVM1?
Question #10
HOTSPOT -
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
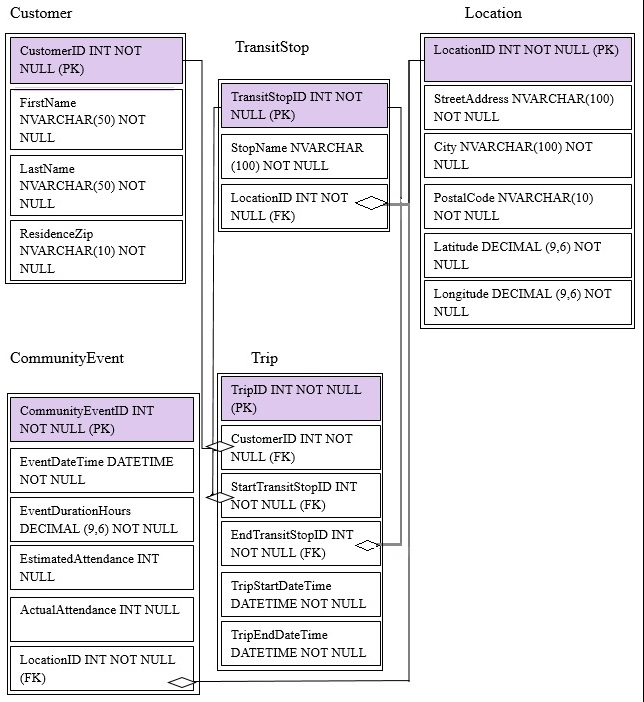
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.

You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
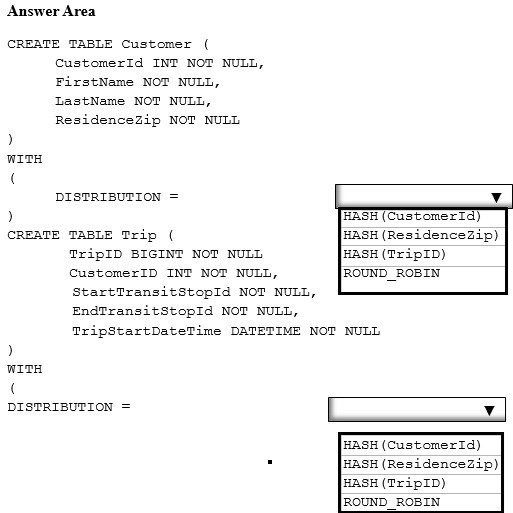
You plan to create a report that will query customer records for a selected ResidenceZip. The report will return customer trips sorted by TripStartDateTime.
You need to specify the distribution clause for each table. The solution must meet the following requirements.
✑ Minimize how long it takes to query the customer information.
✑ Perform the operation as a pass-through query without data movement.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft Azure SQL data warehouse to perform analytics on the transit system of a city. The data warehouse will contain data about customers, trips, and community events.
You have two storage accounts named StorageAccount1 and StorageAccount2. StorageAccount1 is associated to the data warehouse. StorageAccount2 contains weather data files stored in the CSV format. The files have a naming format of city_state_yyymmdd.csv.
Microsoft SQL Server is installed on an Azure virtual machine named AzureVM1.
You are migrating from an existing on premises solution that uses Microsoft SQL Server 2016 Enterprise. The planned schema is shown in the exhibit. (Click the
Exhibit button)
The first column of each table will contain unique values. A table named Customer will contain 12 million rows. A table named Trip will contain 3 billion rows.
You have the following view.
You plan to use Azure Data Factory to perform the following four activities:
✑ Activity1: Invoke an R script to generate a prediction column.
✑ Activity2: Import weather data from a set of CSV files in Azure Blob storage
✑ Activity3: Execute a stored procedure in the Azure SQL data warehouse.
✑ Activity4: Copy data from an Amazon Simple Storage Service (S3).
You plan to detect the following two threat patterns:
✑ Pattern1: A user logs in from two physical locations.
✑ Pattern2: A user attempts to gain elevated permissions.
End of repeated scenario -
You plan to create a report that will query customer records for a selected ResidenceZip. The report will return customer trips sorted by TripStartDateTime.
You need to specify the distribution clause for each table. The solution must meet the following requirements.
✑ Minimize how long it takes to query the customer information.
✑ Perform the operation as a pass-through query without data movement.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
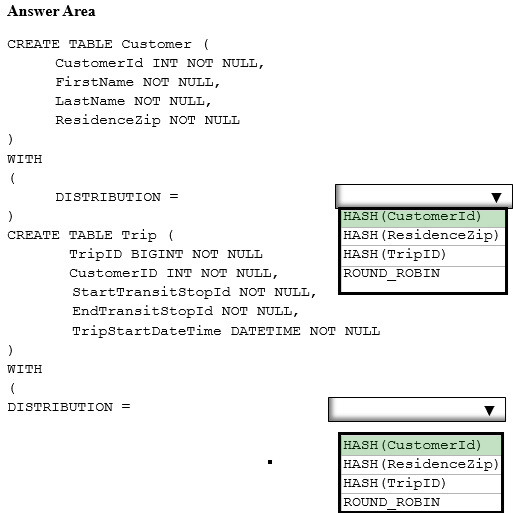
The most common example of when a table distributed by a column will far outperform a Round Robin table is when two large fact tables are joined. For example, if you have an orders table, which is distributed by order_id, and a transactions table, which is also distributed by order_id, when you join your orders table to your transactions table on order_id, this query becomes a pass-through query, which means we eliminate data movement operations. Fewer steps mean a faster query. Less data movement also makes for faster queries.
Incorrect Answers:
Round Robin: Hash distribute large tables
By default, tables are Round Robin distributed. This makes it easy for users to get started creating tables without having to decide how their tables should be distributed. Round Robin tables may perform sufficiently for some workloads, but in most cases selecting a distribution column will perform much better
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-best-practices
The most common example of when a table distributed by a column will far outperform a Round Robin table is when two large fact tables are joined. For example, if you have an orders table, which is distributed by order_id, and a transactions table, which is also distributed by order_id, when you join your orders table to your transactions table on order_id, this query becomes a pass-through query, which means we eliminate data movement operations. Fewer steps mean a faster query. Less data movement also makes for faster queries.
Incorrect Answers:
Round Robin: Hash distribute large tables
By default, tables are Round Robin distributed. This makes it easy for users to get started creating tables without having to decide how their tables should be distributed. Round Robin tables may perform sufficiently for some workloads, but in most cases selecting a distribution column will perform much better
References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-best-practices
All Pages