Microsoft 70-776 Exam Practice Questions (P. 4)
- Full Access (83 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #19
DRAG DROP -
You have a Microsoft Azure SQL data warehouse.
You plan to reference data from Azure Blob storage. The data is stored in the GZIP compressed format. The blob storage requires authentication.
You create a master key for the data warehouse and a database schema.
You need to reference the data without importing the data to the data warehouse.
Which four statements should you execute in sequence? To answer, move the appropriate statements from the list of statements to the answer area and arrange them in the correct order.
Select and Place:
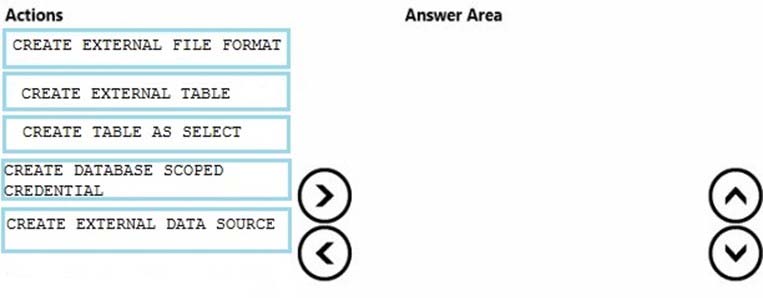
You have a Microsoft Azure SQL data warehouse.
You plan to reference data from Azure Blob storage. The data is stored in the GZIP compressed format. The blob storage requires authentication.
You create a master key for the data warehouse and a database schema.
You need to reference the data without importing the data to the data warehouse.
Which four statements should you execute in sequence? To answer, move the appropriate statements from the list of statements to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
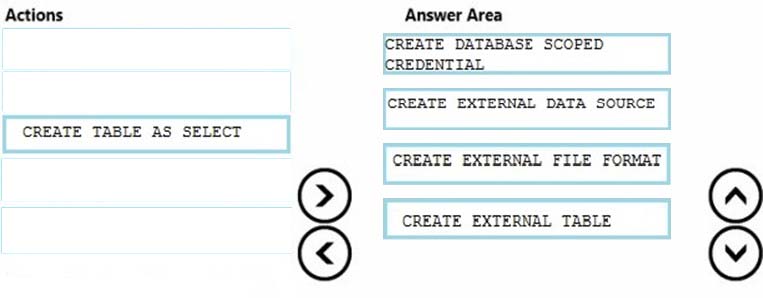
Step 1: CREATE DATABASE SCOPED CREDENTIAL
Step 2: CREATE EXTERNAL DATA SOURCE
Creates an external data source for PolyBase, or Elastic Database queries.
Example Step 1 and Step 2:
-- Create a database scoped credential with Kerberos user name and password.
CREATE DATABASE SCOPED CREDENTIAL HadoopUser1
WITH IDENTITY = '<hadoop_user_name>',
SECRET = '<hadoop_password>';
-- Create an external data source with CREDENTIAL option.
CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://10.10.10.10:8050',
RESOURCE_MANAGER_LOCATION = '10.10.10.10:8050',
CREDENTIAL = HadoopUser1 -
);
Step 3: CREATE EXTERNAL FILE FORMAT
Creates an External File Format object defining external data stored in Hadoop, Azure Blob Storage, or Azure Data Lake Store. Creating an external file format is a prerequisite for creating an External Table. By creating an External File Format, you specify the actual layout of the data referenced by an external table.
Step 4: CREATE EXTERNAL TABLE -
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-file-format-transact-sql
Step 1: CREATE DATABASE SCOPED CREDENTIAL
Step 2: CREATE EXTERNAL DATA SOURCE
Creates an external data source for PolyBase, or Elastic Database queries.
Example Step 1 and Step 2:
-- Create a database scoped credential with Kerberos user name and password.
CREATE DATABASE SCOPED CREDENTIAL HadoopUser1
WITH IDENTITY = '<hadoop_user_name>',
SECRET = '<hadoop_password>';
-- Create an external data source with CREDENTIAL option.
CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://10.10.10.10:8050',
RESOURCE_MANAGER_LOCATION = '10.10.10.10:8050',
CREDENTIAL = HadoopUser1 -
);
Step 3: CREATE EXTERNAL FILE FORMAT
Creates an External File Format object defining external data stored in Hadoop, Azure Blob Storage, or Azure Data Lake Store. Creating an external file format is a prerequisite for creating an External Table. By creating an External File Format, you specify the actual layout of the data referenced by an external table.
Step 4: CREATE EXTERNAL TABLE -
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-file-format-transact-sql
All Pages