Microsoft DP-300 Exam Practice Questions (P. 3)
- Full Access (373 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #22
HOTSPOT -
You are performing exploratory analysis of bus fare data in an Azure Data Lake Storage Gen2 account by using an Azure Synapse Analytics serverless SQL pool.
You execute the Transact-SQL query shown in the following exhibit.
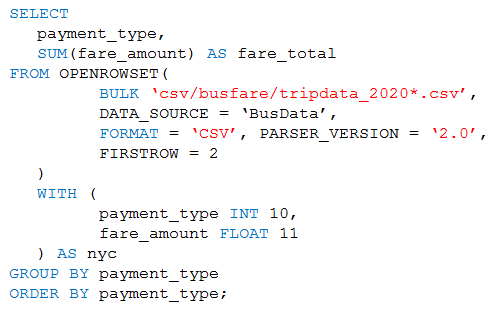
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
Hot Area:
You are performing exploratory analysis of bus fare data in an Azure Data Lake Storage Gen2 account by using an Azure Synapse Analytics serverless SQL pool.
You execute the Transact-SQL query shown in the following exhibit.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
Hot Area:
Correct Answer:
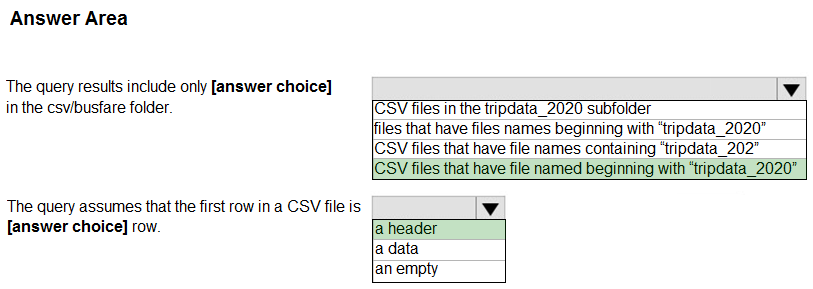
Box 1: CSV files that have file named beginning with "tripdata_2020"
Box 2: a header -
FIRSTROW = 'first_row'
Specifies the number of the first row to load. The default is 1 and indicates the first row in the specified data file. The row numbers are determined by counting the row terminators. FIRSTROW is 1-based.
Example: Option firstrow is used to skip the first row in the CSV file that represents header in this case (firstrow=2). select top 10 * from openrowset( bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv', format = 'csv', parser_version = '2.0', firstrow = 2 ) as rows
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-openrowset https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-single-csv-file
Box 1: CSV files that have file named beginning with "tripdata_2020"
Box 2: a header -
FIRSTROW = 'first_row'
Specifies the number of the first row to load. The default is 1 and indicates the first row in the specified data file. The row numbers are determined by counting the row terminators. FIRSTROW is 1-based.
Example: Option firstrow is used to skip the first row in the CSV file that represents header in this case (firstrow=2). select top 10 * from openrowset( bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv', format = 'csv', parser_version = '2.0', firstrow = 2 ) as rows
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-openrowset https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-single-csv-file
Question #28
HOTSPOT -
You are provisioning an Azure SQL database in the Azure portal as shown in the following exhibit.
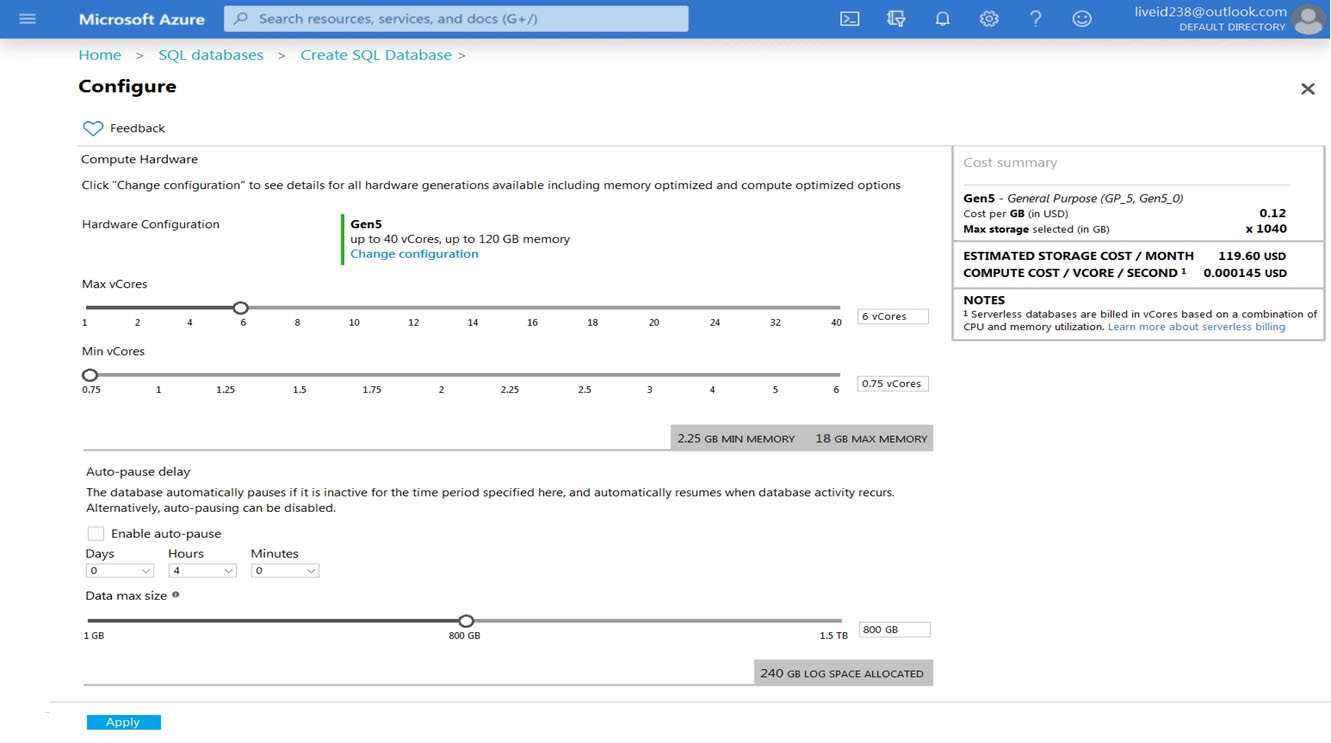
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:

You are provisioning an Azure SQL database in the Azure portal as shown in the following exhibit.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Box 1: no extra time -
Auto Pause is not checked in the exhibit.
Note: If Auto Pause is checked the correct answer is: up to one minute
Box 2: intermittent and unpredictable
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/serverless-tier-overview
Box 1: no extra time -
Auto Pause is not checked in the exhibit.
Note: If Auto Pause is checked the correct answer is: up to one minute
Box 2: intermittent and unpredictable
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/serverless-tier-overview
All Pages