Microsoft 70-475 Exam Practice Questions (P. 4)
- Full Access (42 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #17
HOTSPOT -
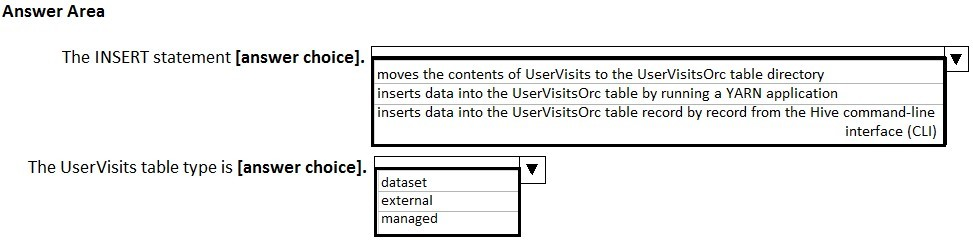
You have the following script.
CREATE TABLE UserVisits (username string, url string, time date)
STORED AS TEXTFILE LOCATION "wasb:///Logs";
CREATE TABLE UserVisitsOrc (username string, url string, time date)
STORED AS ORC;
INSERT INTO TABLE UserVisitsOrc SELECT * FROM UserVisits
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the script.
NOTE: Each correct selection is worth one point.
Hot Area:
You have the following script.
CREATE TABLE UserVisits (username string, url string, time date)
STORED AS TEXTFILE LOCATION "wasb:///Logs";
CREATE TABLE UserVisitsOrc (username string, url string, time date)
STORED AS ORC;
INSERT INTO TABLE UserVisitsOrc SELECT * FROM UserVisits
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the script.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
A table created without the EXTERNAL clause is called a managed table because Hive manages its data.
Reference: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
A table created without the EXTERNAL clause is called a managed table because Hive manages its data.
Reference: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
Question #18
A company named Fabrikam, Inc. has a Microsoft Azure web app. Billions of users visit the app daily.
The web app logs all user activity by using text files in Azure Blob storage. Each day, approximately 200 GB of text files are created.
Fabrikam uses the log files from an Apache Hadoop cluster on Azure HDInsight.
You need to recommend a solution to optimize the storage of the log files for later Hive use.
What is the best property to recommend adding to the Hive table definition to achieve the goal? More than one answer choice may achieve the goal. Select the
BEST answer.
The web app logs all user activity by using text files in Azure Blob storage. Each day, approximately 200 GB of text files are created.
Fabrikam uses the log files from an Apache Hadoop cluster on Azure HDInsight.
You need to recommend a solution to optimize the storage of the log files for later Hive use.
What is the best property to recommend adding to the Hive table definition to achieve the goal? More than one answer choice may achieve the goal. Select the
BEST answer.
- ASTORED AS RCFILE
- BSTORED AS GZIP
- CSTORED AS ORC
- DSTORED AS TEXTFILE
Correct Answer:
C
The Optimized Row Columnar (ORC) file format provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data.
Compared with RCFile format, for example, ORC file format has many advantages such as:
✑ a single file as the output of each task, which reduces the NameNode's load
✑ Hive type support including datetime, decimal, and the complex types (struct, list, map, and union)
✑ light-weight indexes stored within the file
✑ skip row groups that don't pass predicate filtering
✑ seek to a given row
✑ block-mode compression based on data type
✑ run-length encoding for integer columns
✑ dictionary encoding for string columns
✑ concurrent reads of the same file using separate RecordReaders
✑ ability to split files without scanning for markers
bound the amount of memory needed for reading or writing

✑ metadata stored using Protocol Buffers, which allows addition and removal of fields
Reference: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC#LanguageManualORC-ORCFileFormat
C
The Optimized Row Columnar (ORC) file format provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data.
Compared with RCFile format, for example, ORC file format has many advantages such as:
✑ a single file as the output of each task, which reduces the NameNode's load
✑ Hive type support including datetime, decimal, and the complex types (struct, list, map, and union)
✑ light-weight indexes stored within the file
✑ skip row groups that don't pass predicate filtering
✑ seek to a given row
✑ block-mode compression based on data type
✑ run-length encoding for integer columns
✑ dictionary encoding for string columns
✑ concurrent reads of the same file using separate RecordReaders
✑ ability to split files without scanning for markers
bound the amount of memory needed for reading or writing
✑ metadata stored using Protocol Buffers, which allows addition and removal of fields
Reference: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC#LanguageManualORC-ORCFileFormat
All Pages