Microsoft 70-475 Exam Practice Questions (P. 2)
- Full Access (42 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #9
HOTSPOT -
You are designing a solution based on the lambda architecture.
The solution has the following layers:
✑ Batch
✑ Speed
✑ Serving
You are planning the data ingestion process and the query execution.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:

You are designing a solution based on the lambda architecture.
The solution has the following layers:
✑ Batch
✑ Speed
✑ Serving
You are planning the data ingestion process and the query execution.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Box 1: No -
Box 2: No -
Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from the processed data.
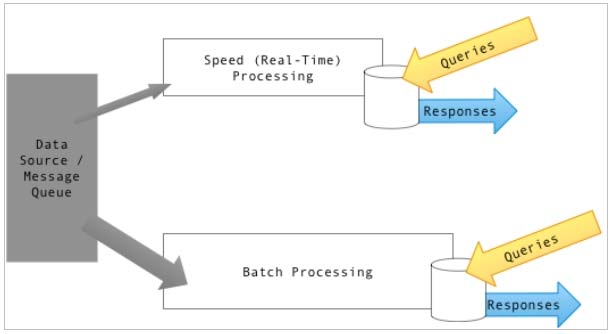
Box 3: Yes.
We are excited to announce Interactive Queries, a new feature for stream processing with Apache Kafka. Interactive Queries allows you to get more than just processing from streaming.
Note: Lambda architecture is a popular choice where you see stream data pipelines applied (speed layer). Architects can combine Apache Kafka or Azure Event
Hubs (ingest) with Apache Storm (event processing), Apache HBase (speed layer), Hadoop for storing the master dataset (batch layer), and, finally, Microsoft
Power BI for reporting and visualization (serving layer).
Reference: https://www.confluent.io/blog/unifying-stream-processing-and-interactive-queries-in-apache-kafka/ https://en.wikipedia.org/wiki/Lambda_architecture
Box 1: No -
Box 2: No -
Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from the processed data.
Box 3: Yes.
We are excited to announce Interactive Queries, a new feature for stream processing with Apache Kafka. Interactive Queries allows you to get more than just processing from streaming.
Note: Lambda architecture is a popular choice where you see stream data pipelines applied (speed layer). Architects can combine Apache Kafka or Azure Event
Hubs (ingest) with Apache Storm (event processing), Apache HBase (speed layer), Hadoop for storing the master dataset (batch layer), and, finally, Microsoft
Power BI for reporting and visualization (serving layer).
Reference: https://www.confluent.io/blog/unifying-stream-processing-and-interactive-queries-in-apache-kafka/ https://en.wikipedia.org/wiki/Lambda_architecture
Question #10
DRAG DROP -
You have a web app that accepts user input, and then uses a Microsoft Azure Machine Learning model to predict a characteristic of the user.
You need to perform the following operations:
✑ Track the number of web app users from month to month.
✑ Track the number of successful predictions made during the last minute.
✑ Create a dashboard showcasing the analytics for the predictions and the web app usage.
Which lambda layer should you query for each operation? To answer, drag the appropriate layers to the correct operations. Each layer may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

You have a web app that accepts user input, and then uses a Microsoft Azure Machine Learning model to predict a characteristic of the user.
You need to perform the following operations:
✑ Track the number of web app users from month to month.
✑ Track the number of successful predictions made during the last minute.
✑ Create a dashboard showcasing the analytics for the predictions and the web app usage.
Which lambda layer should you query for each operation? To answer, drag the appropriate layers to the correct operations. Each layer may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:

Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation
Box 1: Speed -
The speed layer processes data streams in real time and without the requirements of fix-ups or completeness. This layer sacrifices throughput as it aims to minimize latency by providing real-time views into the most recent data.
Box 2: Batch -
The batch layer precomputes results using a distributed processing system that can handle very large quantities of data. The batch layer aims at perfect accuracy by being able to process all available data when generating views.
Box 3: Serving -
Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from the processed data.
Reference: https://en.wikipedia.org/wiki/Lambda_architecture
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation
Box 1: Speed -
The speed layer processes data streams in real time and without the requirements of fix-ups or completeness. This layer sacrifices throughput as it aims to minimize latency by providing real-time views into the most recent data.
Box 2: Batch -
The batch layer precomputes results using a distributed processing system that can handle very large quantities of data. The batch layer aims at perfect accuracy by being able to process all available data when generating views.
Box 3: Serving -
Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from the processed data.
Reference: https://en.wikipedia.org/wiki/Lambda_architecture
All Pages