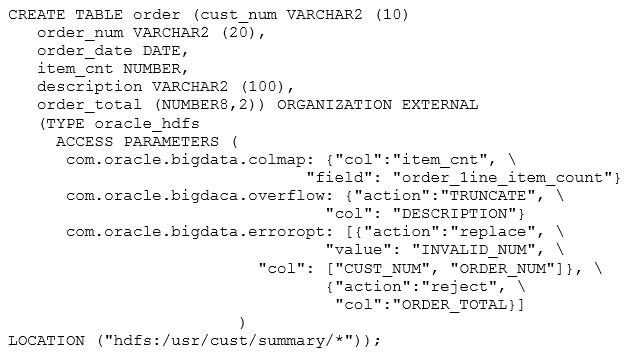
What is the output of the following six commands when they are executed by using the Oracle XML Extensions for Hive in the Oracle XQuery for Hadoop
Connector?
1. $ echo "xxx" > src.txt
2. $ hive --auxpath $OXH_HOME/hive/lib -i $OXH_HOME/hive/init.sql
3. hive> CREATE TABLE src (dummy STRING);
4. hive> LOAD DATA LOCAL INPATH 'src.txt' OVERWRITE INTO TABLE src;
5. hive> SELECT * FROM src;
OK -
xxx
6. hive> SELECT xml_query ("x/y", "<x><y>123</y><z>456</z></x>") FROM src;
Correct Answer:
B
Using the Hive Extensions -
To enable the Oracle XQuery for Hadoop extensions, use the --auxpath and -i arguments when starting Hive:
$ hive --auxpath $OXH_HOME/hive/lib -i $OXH_HOME/hive/init.sql
The first time you use the extensions, verify that they are accessible. The following procedure creates a table named SRC, loads one row into it, and calls the xml_query function.
To verify that the extensions are accessible:
1. Log in to an Oracle Big Data Appliance server where you plan to work.
2. Create a text file named src.txt that contains one line:
$ echo "XXX" > src.txt
3. Start the Hive command-line interface (CLI):
$ hive --auxpath $OXH_HOME/hive/lib -i $OXH_HOME/hive/init.sql
The init.sql file contains the CREATE TEMPORARY FUNCTION statements that declare the XML functions.
4. Create a simple table:
hive> CREATE TABLE src(dummy STRING);
The SRC table is needed only to fulfill a SELECT syntax requirement. It is like the DUAL table in Oracle Database, which is referenced in SELECT statements to test SQL functions.
5. Load data from src.txt into the table:
hive> LOAD DATA LOCAL INPATH 'src.txt' OVERWRITE INTO TABLE src;
6. Query the table using Hive SELECT statements:
hive> SELECT * FROM src;
OK -
xxx
7. Call an Oracle XQuery for Hadoop function for Hive. This example calls the xml_query function to parse an XML string: hive> SELECT xml_query("x/y", "<x><y>123</y><z>456</z></x>") FROM src;
.
.
.
["123"]
If the extensions are accessible, then the query returns ["123"], as shown in the example
References:
https://docs.oracle.com/cd/E53356_01/doc.30/e53067/oxh_hive.htm#BDCUG693
Show Answer