Microsoft 70-767 Exam Practice Questions (P. 4)
- Full Access (142 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #17
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The
Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it to daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
✑ Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible.
✑ Partition the Fact.Order table and retain a total of seven years of data.
✑ Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.

✑ Incrementally load all tables in the database and ensure that all incremental changes are processed.
✑ Maximize the performance during the data loading process for the Fact.Order partition.
✑ Ensure that historical data remains online and available for querying.
✑ Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to optimize the storage for the data warehouse.
What change should you make?
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The
Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it to daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
✑ Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible.
✑ Partition the Fact.Order table and retain a total of seven years of data.
✑ Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
✑ Incrementally load all tables in the database and ensure that all incremental changes are processed.
✑ Maximize the performance during the data loading process for the Fact.Order partition.
✑ Ensure that historical data remains online and available for querying.
✑ Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to optimize the storage for the data warehouse.
What change should you make?
Question #18
HOTSPOT -
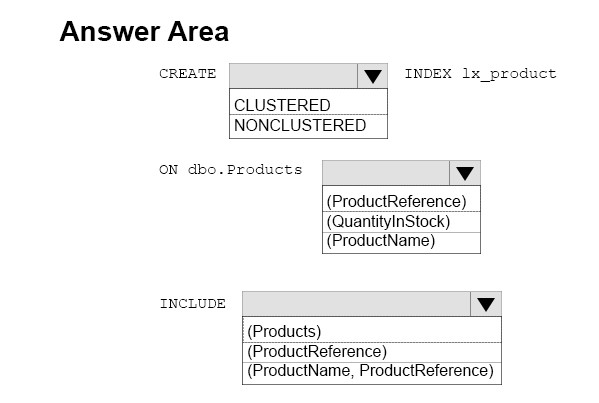
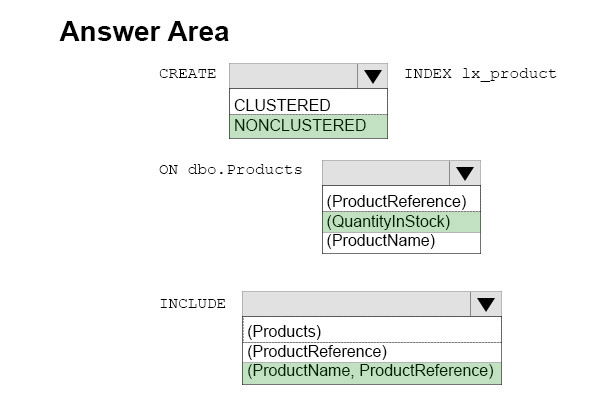
You manage an inventory system that has a table named Products. The Products table has several hundred columns.
You generate a report that relates two columns named ProductReference and ProductName from the Products table. The result is sorted by a column named
QuantityInStock from largest to smallest.
You need to create an index that the report can use.
How should you complete the Transact-SQL statement? To answer, select the appropriate Transact-SQL segments in the answer area.
Hot Area:
You manage an inventory system that has a table named Products. The Products table has several hundred columns.
You generate a report that relates two columns named ProductReference and ProductName from the Products table. The result is sorted by a column named
QuantityInStock from largest to smallest.
You need to create an index that the report can use.
How should you complete the Transact-SQL statement? To answer, select the appropriate Transact-SQL segments in the answer area.
Hot Area:
Question #19
HOTSPOT -
You manage a data warehouse in a Microsoft SQL Server instance. Company employee information is imported from the human resources system to a table named Employee in the data warehouse instance. The Employee table was created by running the query shown in the Employee Schema exhibit. (Click the
Exhibit button.)

The personal identification number is stored in a column named EmployeeSSN. All values in the EmployeeSSN column must be unique.
When importing employee data, you receive the error message shown in the SQL Error exhibit. (Click the Exhibit button.).
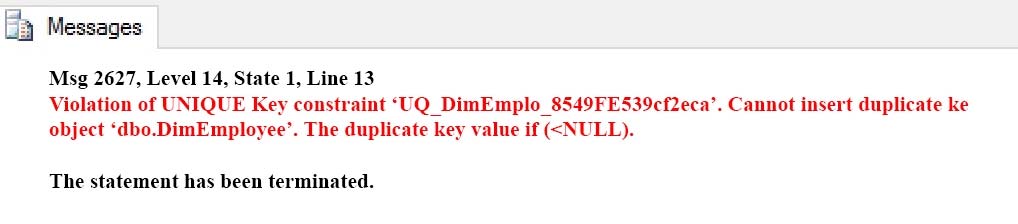
You determine that the Transact-SQL statement shown in the Data Load exhibit is the cause of the error. (Click the Exhibit button.)

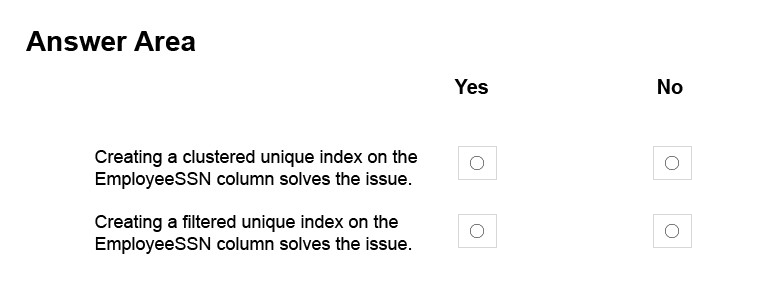
You remove the constraint on the EmployeeSSN column. You need to ensure that values in the EmployeeSSN column are unique.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
You manage a data warehouse in a Microsoft SQL Server instance. Company employee information is imported from the human resources system to a table named Employee in the data warehouse instance. The Employee table was created by running the query shown in the Employee Schema exhibit. (Click the
Exhibit button.)
The personal identification number is stored in a column named EmployeeSSN. All values in the EmployeeSSN column must be unique.
When importing employee data, you receive the error message shown in the SQL Error exhibit. (Click the Exhibit button.).
You determine that the Transact-SQL statement shown in the Data Load exhibit is the cause of the error. (Click the Exhibit button.)
You remove the constraint on the EmployeeSSN column. You need to ensure that values in the EmployeeSSN column are unique.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
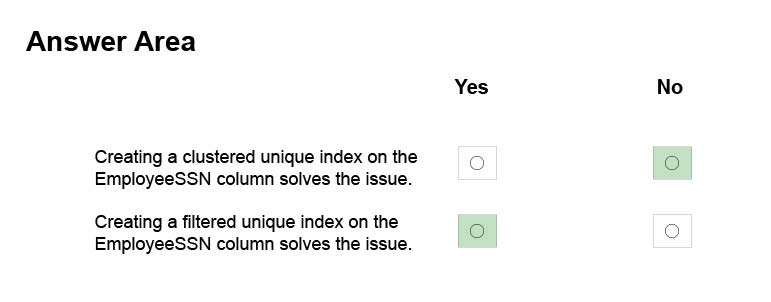
With the ANSI standards SQL:92, SQL:1999 and SQL:2003, an UNIQUE constraint must disallow duplicate non-NULL values but accept multiple NULL values.
In the Microsoft world of SQL Server however, a single NULL is allowed but multiple NULLs are not.
From SQL Server 2008, you can define a unique filtered index based on a predicate that excludes NULLs.
References: https://stackoverflow.com/questions/767657/how-do-i-create-a-unique-constraint-that-also-allows-nulls
With the ANSI standards SQL:92, SQL:1999 and SQL:2003, an UNIQUE constraint must disallow duplicate non-NULL values but accept multiple NULL values.
In the Microsoft world of SQL Server however, a single NULL is allowed but multiple NULLs are not.
From SQL Server 2008, you can define a unique filtered index based on a predicate that excludes NULLs.
References: https://stackoverflow.com/questions/767657/how-do-i-create-a-unique-constraint-that-also-allows-nulls
Question #20
DRAG DROP -
You have a data warehouse.
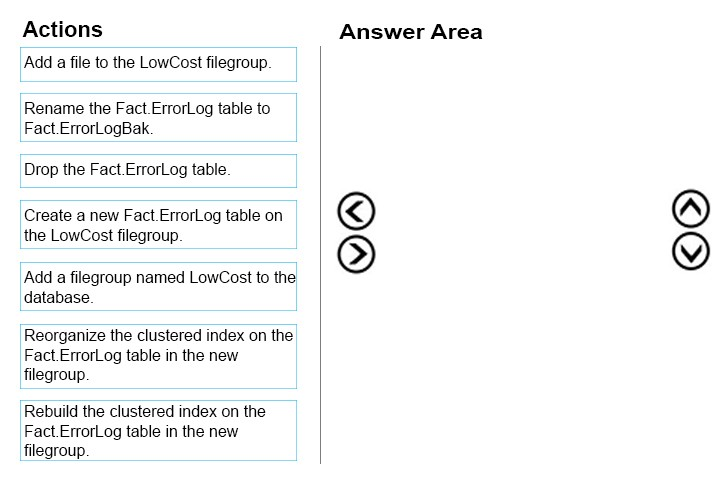
You need to move a table named Fact.ErrorLog to a new filegroup named LowCost.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
You have a data warehouse.
You need to move a table named Fact.ErrorLog to a new filegroup named LowCost.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
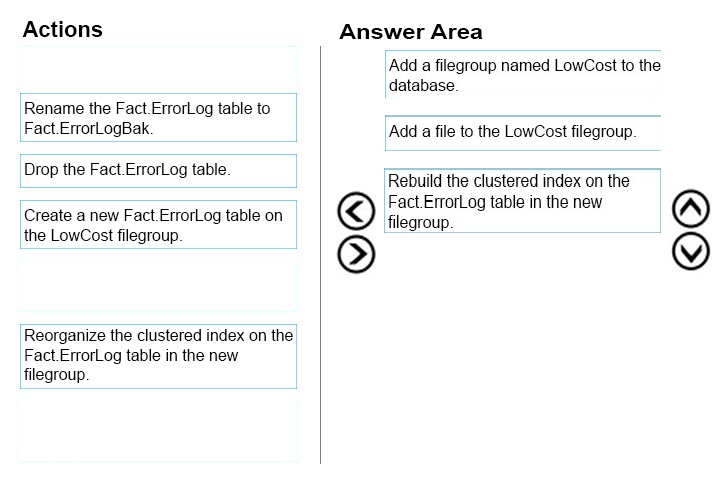
Step 1: Add a filegroup named LowCost to the database.
First create a new filegroup.
Step 2:
The next stage is to go to the "˜Files' page in the same Properties window and add a file to the filegroup (a filegroup always contains one or more files)
Step 3:
To move a table to a different filegroup involves moving the table's clustered index to the new filegroup. While this may seem strange at first this is not that surprising when you remember that the leaf level of the clustered index actually contains the table data. Moving the clustered index can be done in a single statement using the DROP_EXISTING clause as follows (using one of the AdventureWorks2008R2 tables as an example) :
CREATE UNIQUE CLUSTERED INDEX PK_Department_DepartmentID
ON HumanResources.Department(DepartmentID)
WITH (DROP_EXISTING=ON,ONLINE=ON) ON SECONDARY
This recreates the same index but on the SECONDARY filegroup.
References: http://www.sqlmatters.com/Articles/Moving%20a%20Table%20to%20a%20Different%20Filegroup.aspx
Step 1: Add a filegroup named LowCost to the database.
First create a new filegroup.
Step 2:
The next stage is to go to the "˜Files' page in the same Properties window and add a file to the filegroup (a filegroup always contains one or more files)
Step 3:
To move a table to a different filegroup involves moving the table's clustered index to the new filegroup. While this may seem strange at first this is not that surprising when you remember that the leaf level of the clustered index actually contains the table data. Moving the clustered index can be done in a single statement using the DROP_EXISTING clause as follows (using one of the AdventureWorks2008R2 tables as an example) :
CREATE UNIQUE CLUSTERED INDEX PK_Department_DepartmentID
ON HumanResources.Department(DepartmentID)
WITH (DROP_EXISTING=ON,ONLINE=ON) ON SECONDARY
This recreates the same index but on the SECONDARY filegroup.
References: http://www.sqlmatters.com/Articles/Moving%20a%20Table%20to%20a%20Different%20Filegroup.aspx
All Pages