Amazon AWS Certified Machine Learning - Specialty Exam Practice Questions (P. 4)
- Full Access (369 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #31
A monitoring service generates 1 TB of scale metrics record data every minute. A Research team performs queries on this data using Amazon Athena. The queries run slowly due to the large volume of data, and the team requires better performance.
How should the records be stored in Amazon S3 to improve query performance?
How should the records be stored in Amazon S3 to improve query performance?
send
light_mode
delete
Question #32
Machine Learning Specialist is working with a media company to perform classification on popular articles from the company's website. The company is using random forests to classify how popular an article will be before it is published. A sample of the data being used is below.
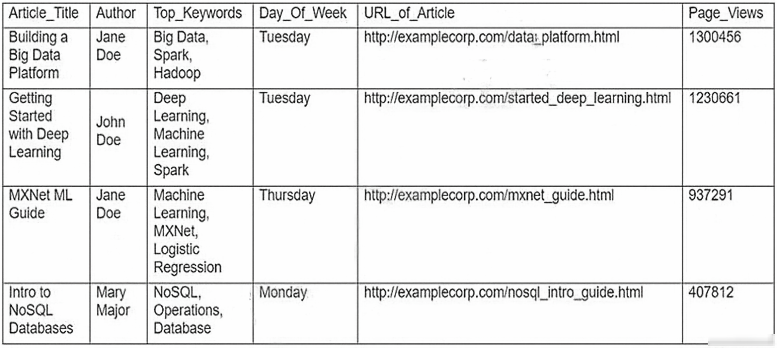
Given the dataset, the Specialist wants to convert the Day_Of_Week column to binary values.
What technique should be used to convert this column to binary values?
Given the dataset, the Specialist wants to convert the Day_Of_Week column to binary values.
What technique should be used to convert this column to binary values?
- ABinarization
- BOne-hot encodingMost Voted
- CTokenization
- DNormalization transformation
Correct Answer:
B
B
send
light_mode
delete
Question #33
A gaming company has launched an online game where people can start playing for free, but they need to pay if they choose to use certain features. The company needs to build an automated system to predict whether or not a new user will become a paid user within 1 year. The company has gathered a labeled dataset from 1 million users.
The training dataset consists of 1,000 positive samples (from users who ended up paying within 1 year) and 999,000 negative samples (from users who did not use any paid features). Each data sample consists of 200 features including user age, device, location, and play patterns.
Using this dataset for training, the Data Science team trained a random forest model that converged with over 99% accuracy on the training set. However, the prediction results on a test dataset were not satisfactory
Which of the following approaches should the Data Science team take to mitigate this issue? (Choose two.)
The training dataset consists of 1,000 positive samples (from users who ended up paying within 1 year) and 999,000 negative samples (from users who did not use any paid features). Each data sample consists of 200 features including user age, device, location, and play patterns.
Using this dataset for training, the Data Science team trained a random forest model that converged with over 99% accuracy on the training set. However, the prediction results on a test dataset were not satisfactory
Which of the following approaches should the Data Science team take to mitigate this issue? (Choose two.)
- AAdd more deep trees to the random forest to enable the model to learn more features.
- BInclude a copy of the samples in the test dataset in the training dataset.
- CGenerate more positive samples by duplicating the positive samples and adding a small amount of noise to the duplicated data.Most Voted
- DChange the cost function so that false negatives have a higher impact on the cost value than false positives.Most Voted
- EChange the cost function so that false positives have a higher impact on the cost value than false negatives.
Correct Answer:
CD
CD
send
light_mode
delete
Question #34
A Data Scientist is developing a machine learning model to predict future patient outcomes based on information collected about each patient and their treatment plans. The model should output a continuous value as its prediction. The data available includes labeled outcomes for a set of 4,000 patients. The study was conducted on a group of individuals over the age of 65 who have a particular disease that is known to worsen with age.
Initial models have performed poorly. While reviewing the underlying data, the Data Scientist notices that, out of 4,000 patient observations, there are 450 where the patient age has been input as 0. The other features for these observations appear normal compared to the rest of the sample population
How should the Data Scientist correct this issue?
Initial models have performed poorly. While reviewing the underlying data, the Data Scientist notices that, out of 4,000 patient observations, there are 450 where the patient age has been input as 0. The other features for these observations appear normal compared to the rest of the sample population
How should the Data Scientist correct this issue?
- ADrop all records from the dataset where age has been set to 0.
- BReplace the age field value for records with a value of 0 with the mean or median value from the datasetMost Voted
- CDrop the age feature from the dataset and train the model using the rest of the features.
- DUse k-means clustering to handle missing features
Correct Answer:
B
B
send
light_mode
delete
Question #35
A Data Science team is designing a dataset repository where it will store a large amount of training data commonly used in its machine learning models. As Data
Scientists may create an arbitrary number of new datasets every day, the solution has to scale automatically and be cost-effective. Also, it must be possible to explore the data using SQL.
Which storage scheme is MOST adapted to this scenario?
Scientists may create an arbitrary number of new datasets every day, the solution has to scale automatically and be cost-effective. Also, it must be possible to explore the data using SQL.
Which storage scheme is MOST adapted to this scenario?
- AStore datasets as files in Amazon S3.Most Voted
- BStore datasets as files in an Amazon EBS volume attached to an Amazon EC2 instance.
- CStore datasets as tables in a multi-node Amazon Redshift cluster.
- DStore datasets as global tables in Amazon DynamoDB.
Correct Answer:
A
A
send
light_mode
delete
Question #36
A Machine Learning Specialist deployed a model that provides product recommendations on a company's website. Initially, the model was performing very well and resulted in customers buying more products on average. However, within the past few months, the Specialist has noticed that the effect of product recommendations has diminished and customers are starting to return to their original habits of spending less. The Specialist is unsure of what happened, as the model has not changed from its initial deployment over a year ago.
Which method should the Specialist try to improve model performance?
Which method should the Specialist try to improve model performance?
- AThe model needs to be completely re-engineered because it is unable to handle product inventory changes.
- BThe model's hyperparameters should be periodically updated to prevent drift.
- CThe model should be periodically retrained from scratch using the original data while adding a regularization term to handle product inventory changes
- DThe model should be periodically retrained using the original training data plus new data as product inventory changes.Most Voted
Correct Answer:
D
D
send
light_mode
delete
Question #37
A Machine Learning Specialist working for an online fashion company wants to build a data ingestion solution for the company's Amazon S3-based data lake.
The Specialist wants to create a set of ingestion mechanisms that will enable future capabilities comprised of:
✑ Real-time analytics
✑ Interactive analytics of historical data
✑ Clickstream analytics
✑ Product recommendations
Which services should the Specialist use?
The Specialist wants to create a set of ingestion mechanisms that will enable future capabilities comprised of:
✑ Real-time analytics
✑ Interactive analytics of historical data
✑ Clickstream analytics
✑ Product recommendations
Which services should the Specialist use?
- AAWS Glue as the data catalog; Amazon Kinesis Data Streams and Amazon Kinesis Data Analytics for real-time data insights; Amazon Kinesis Data Firehose for delivery to Amazon ES for clickstream analytics; Amazon EMR to generate personalized product recommendationsMost Voted
- BAmazon Athena as the data catalog: Amazon Kinesis Data Streams and Amazon Kinesis Data Analytics for near-real-time data insights; Amazon Kinesis Data Firehose for clickstream analytics; AWS Glue to generate personalized product recommendations
- CAWS Glue as the data catalog; Amazon Kinesis Data Streams and Amazon Kinesis Data Analytics for historical data insights; Amazon Kinesis Data Firehose for delivery to Amazon ES for clickstream analytics; Amazon EMR to generate personalized product recommendations
- DAmazon Athena as the data catalog; Amazon Kinesis Data Streams and Amazon Kinesis Data Analytics for historical data insights; Amazon DynamoDB streams for clickstream analytics; AWS Glue to generate personalized product recommendations
Correct Answer:
A
A
send
light_mode
delete
Question #38
A company is observing low accuracy while training on the default built-in image classification algorithm in Amazon SageMaker. The Data Science team wants to use an Inception neural network architecture instead of a ResNet architecture.
Which of the following will accomplish this? (Choose two.)
Which of the following will accomplish this? (Choose two.)
- ACustomize the built-in image classification algorithm to use Inception and use this for model training.
- BCreate a support case with the SageMaker team to change the default image classification algorithm to Inception.
- CBundle a Docker container with TensorFlow Estimator loaded with an Inception network and use this for model training.Most Voted
- DUse custom code in Amazon SageMaker with TensorFlow Estimator to load the model with an Inception network, and use this for model training.Most Voted
- EDownload and apt-get install the inception network code into an Amazon EC2 instance and use this instance as a Jupyter notebook in Amazon SageMaker.
Correct Answer:
CD
CD
send
light_mode
delete
Question #39
A Machine Learning Specialist built an image classification deep learning model. However, the Specialist ran into an overfitting problem in which the training and testing accuracies were 99% and 75%, respectively.
How should the Specialist address this issue and what is the reason behind it?
How should the Specialist address this issue and what is the reason behind it?
- AThe learning rate should be increased because the optimization process was trapped at a local minimum.
- BThe dropout rate at the flatten layer should be increased because the model is not generalized enough.Most Voted
- CThe dimensionality of dense layer next to the flatten layer should be increased because the model is not complex enough.
- DThe epoch number should be increased because the optimization process was terminated before it reached the global minimum.
Correct Answer:
D
Reference:
https://www.tensorflow.org/tutorials/keras/overfit_and_underfit
D
Reference:
https://www.tensorflow.org/tutorials/keras/overfit_and_underfit
send
light_mode
delete
Question #40
A Machine Learning team uses Amazon SageMaker to train an Apache MXNet handwritten digit classifier model using a research dataset. The team wants to receive a notification when the model is overfitting. Auditors want to view the Amazon SageMaker log activity report to ensure there are no unauthorized API calls.
What should the Machine Learning team do to address the requirements with the least amount of code and fewest steps?
What should the Machine Learning team do to address the requirements with the least amount of code and fewest steps?
- AImplement an AWS Lambda function to log Amazon SageMaker API calls to Amazon S3. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
- BUse AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.Most Voted
- CImplement an AWS Lambda function to log Amazon SageMaker API calls to AWS CloudTrail. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
- DUse AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Set up Amazon SNS to receive a notification when the model is overfitting
Correct Answer:
B
B
send
light_mode
delete
All Pages