Oracle 1z0-053 Exam Practice Questions (P. 1)
- Full Access (706 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #1
The INV_HISTORY table is created using the command:

The following data has been inserted into the INV_HISTORY table:

You would like to store the data belonging to the year 2006 in a single partition and issue the command:
SQL> ALTER TABLE inv_history -
MERGE PARTITIONS -
FOR(TO_DATE('15-feb-2006','dd-mon-yyyy')),
FOR(TO_DATE('15-apr-2006'))
INTO PARTITION sys_py;
What would be the outcome of this command?
The following data has been inserted into the INV_HISTORY table:
You would like to store the data belonging to the year 2006 in a single partition and issue the command:
SQL> ALTER TABLE inv_history -
MERGE PARTITIONS -
FOR(TO_DATE('15-feb-2006','dd-mon-yyyy')),
FOR(TO_DATE('15-apr-2006'))
INTO PARTITION sys_py;
What would be the outcome of this command?
Question #10
You are managing an ASM instance. You previously issued the following statements:
ALTER DISKGROUP dg1 DROP DISK disk2;
ALTER DISKGROUP dg1 DROP DISK disk3;
ALTER DISKGROUP dg1 DROP DISK disk5;
You want to cancel the disk drops that are pending for the DG1 disk group.
Which statement should you issue?
ALTER DISKGROUP dg1 DROP DISK disk2;
ALTER DISKGROUP dg1 DROP DISK disk3;
ALTER DISKGROUP dg1 DROP DISK disk5;
You want to cancel the disk drops that are pending for the DG1 disk group.
Which statement should you issue?
- AALTER DISKGROUP dg1 UNDROP disk2, disk3, disk5;
- BALTER DISKGROUP dg1 UNDROP;
- CALTER DISKGROUP dg1 UNDROP DISKS;
- DYou cannot cancel the pending disk drops.
Correct Answer:
C
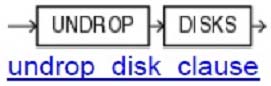
Use this clause to cancel the drop of disks from the disk group. You can cancel the pending drop of all the disks in one or more disk groups (by specifying diskgroup_name) or of all the disks in all disk groups (by specifying ALL).
This clause is not relevant for disks that have already been completely dropped from the disk group or for disk groups that have been completely dropped. This clause results in a long-running operation. You can see the status of the operation by querying the V$ASM_OPERATION dynamic performance view.
C
Use this clause to cancel the drop of disks from the disk group. You can cancel the pending drop of all the disks in one or more disk groups (by specifying diskgroup_name) or of all the disks in all disk groups (by specifying ALL).
This clause is not relevant for disks that have already been completely dropped from the disk group or for disk groups that have been completely dropped. This clause results in a long-running operation. You can see the status of the operation by querying the V$ASM_OPERATION dynamic performance view.
All Pages