Microsoft DP-100 Exam Practice Questions (P. 5)
- Full Access (528 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #42
You are making use of the Azure Machine Learning to designer construct an experiment.
After dividing a dataset into training and testing sets, you configure the algorithm to be Two-Class Boosted Decision Tree.
You are preparing to ascertain the Area Under the Curve (AUC).
Which of the following is a sequential combination of the models required to achieve your goal?
After dividing a dataset into training and testing sets, you configure the algorithm to be Two-Class Boosted Decision Tree.
You are preparing to ascertain the Area Under the Curve (AUC).
Which of the following is a sequential combination of the models required to achieve your goal?
- ATrain, Score, Evaluate.
- BScore, Evaluate, Train.
- CEvaluate, Export Data, Train.
- DTrain, Score, Export Data.
Correct Answer:
A
A
 GPT
GPT
To achieve the Area Under the Curve (AUC) with Azure Machine Learning, the correct sequence involves first training the model using the dataset ('Train'), which is followed by predicting the outputs using the test data ('Score'), and finally, evaluating the model performance ('Evaluate'). This logical order ensures that the model is properly trained before assessments and that the evaluation accurately reflects the model's ability to generalize to new data. This sequential flow is essential for accurately testing the effectiveness of the Two-Class Boosted Decision Tree algorithm.
Question #43
You are developing a hands-on workshop to introduce Docker for Windows to attendees.
You need to ensure that workshop attendees can install Docker on their devices.
Which two prerequisite components should attendees install on the devices? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to ensure that workshop attendees can install Docker on their devices.
Which two prerequisite components should attendees install on the devices? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- AMicrosoft Hardware-Assisted Virtualization Detection Tool
- BKitematic
- CBIOS-enabled virtualization
- DVirtualBox
- EWindows 10 64-bit Professional
Correct Answer:
CE
C: Make sure your Windows system supports Hardware Virtualization Technology and that virtualization is enabled.
Ensure that hardware virtualization support is turned on in the BIOS settings. For example:
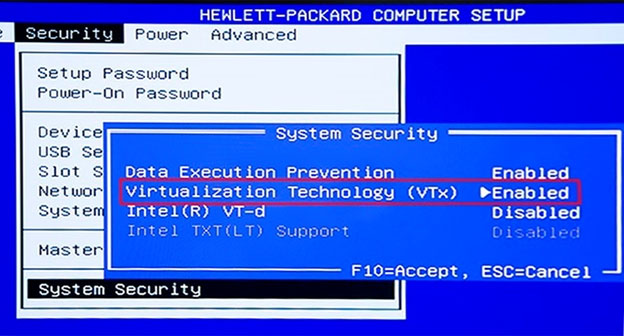
E: To run Docker, your machine must have a 64-bit operating system running Windows 7 or higher.
Reference:
https://docs.docker.com/toolbox/toolbox_install_windows/
https://blogs.technet.microsoft.com/canitpro/2015/09/08/step-by-step-enabling-hyper-v-for-use-on-windows-10/
CE
C: Make sure your Windows system supports Hardware Virtualization Technology and that virtualization is enabled.
Ensure that hardware virtualization support is turned on in the BIOS settings. For example:
E: To run Docker, your machine must have a 64-bit operating system running Windows 7 or higher.
Reference:
https://docs.docker.com/toolbox/toolbox_install_windows/
https://blogs.technet.microsoft.com/canitpro/2015/09/08/step-by-step-enabling-hyper-v-for-use-on-windows-10/
Question #45
DRAG DROP -
You are building an intelligent solution using machine learning models.
The environment must support the following requirements:
✑ Data scientists must build notebooks in a cloud environment
✑ Data scientists must use automatic feature engineering and model building in machine learning pipelines.
✑ Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation.
✑ Notebooks must be exportable to be version controlled locally.
You need to create the environment.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

You are building an intelligent solution using machine learning models.
The environment must support the following requirements:
✑ Data scientists must build notebooks in a cloud environment
✑ Data scientists must use automatic feature engineering and model building in machine learning pipelines.
✑ Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation.
✑ Notebooks must be exportable to be version controlled locally.
You need to create the environment.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
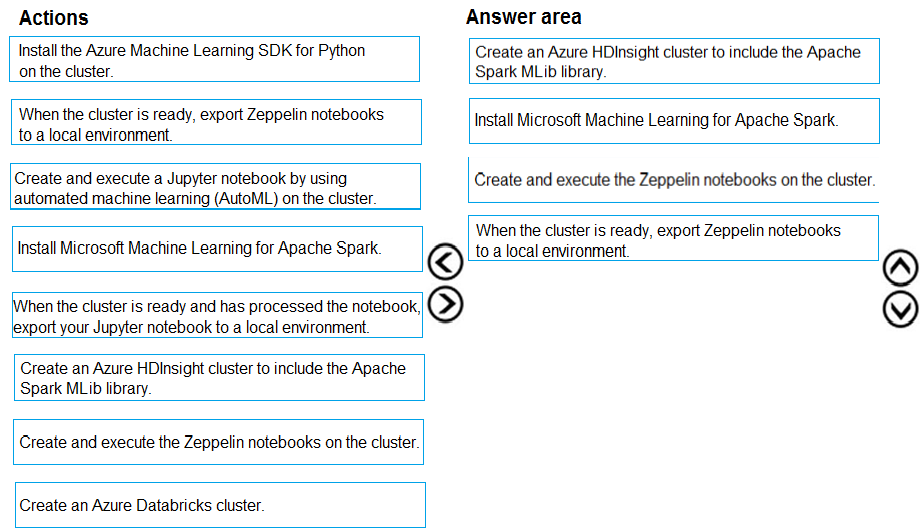
Step 1: Create an Azure HDInsight cluster to include the Apache Spark Mlib library
Step 2: Install Microsot Machine Learning for Apache Spark
You install AzureML on your Azure HDInsight cluster.
Microsoft Machine Learning for Apache Spark (MMLSpark) provides a number of deep learning and data science tools for Apache Spark, including seamless integration of Spark Machine Learning pipelines with Microsoft Cognitive Toolkit (CNTK) and OpenCV, enabling you to quickly create powerful, highly-scalable predictive and analytical models for large image and text datasets.
Step 3: Create and execute the Zeppelin notebooks on the cluster
Step 4: When the cluster is ready, export Zeppelin notebooks to a local environment.
Notebooks must be exportable to be version controlled locally.
Reference:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-zeppelin-notebook https://azuremlbuild.blob.core.windows.net/pysparkapi/intro.html
Step 1: Create an Azure HDInsight cluster to include the Apache Spark Mlib library
Step 2: Install Microsot Machine Learning for Apache Spark
You install AzureML on your Azure HDInsight cluster.
Microsoft Machine Learning for Apache Spark (MMLSpark) provides a number of deep learning and data science tools for Apache Spark, including seamless integration of Spark Machine Learning pipelines with Microsoft Cognitive Toolkit (CNTK) and OpenCV, enabling you to quickly create powerful, highly-scalable predictive and analytical models for large image and text datasets.
Step 3: Create and execute the Zeppelin notebooks on the cluster
Step 4: When the cluster is ready, export Zeppelin notebooks to a local environment.
Notebooks must be exportable to be version controlled locally.
Reference:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-zeppelin-notebook https://azuremlbuild.blob.core.windows.net/pysparkapi/intro.html
All Pages