Google Professional Cloud Developer Exam Practice Questions (P. 3)
- Full Access (379 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #23
You want to use the Stackdriver Logging Agent to send an application's log file to Stackdriver from a Compute Engine virtual machine instance.
After installing the Stackdriver Logging Agent, what should you do first?
After installing the Stackdriver Logging Agent, what should you do first?
- AEnable the Error Reporting API on the project.
- BGrant the instance full access to all Cloud APIs.
- CConfigure the application log file as a custom source.
- DCreate a Stackdriver Logs Export Sink with a filter that matches the application's log entries.
Correct Answer:
C
 GPT
GPT
To securely manage your application's logs using the Stackdriver Logging Agent on a Compute Engine instance, it is critical to authorize the instance appropriately. Although granting full access to all Cloud APIs, as mentioned in choice B, may seem broad, it's essential for the initial setup to ensure that the agent functions correctly. However, after this setup phase, you should review and restrict permissions to adhere more closely to the principle of least privilege, reducing the scope to what's necessary for ongoing operations. It's a balancing act between initial functional requirements and long-term security best practices.
Question #24
Your company has a BigQuery data mart that provides analytics information to hundreds of employees. One user of wants to run jobs without interrupting important workloads. This user isn't concerned about the time it takes to run these jobs. You want to fulfill this request while minimizing cost to the company and the effort required on your part.
What should you do?
What should you do?
- AAsk the user to run the jobs as batch jobs.
- BCreate a separate project for the user to run jobs.
- CAdd the user as a job.user role in the existing project.
- DAllow the user to run jobs when important workloads are not running.
Correct Answer:
A
GPT
Option B, creating a separate project for the user, might initially seem effective for isolating workloads; however, it can indeed lead to increased costs and complexity in managing multiple projects. On the other hand, configuring jobs to run as batch jobs (Option A) is a more streamlined approach that aligns well with minimizing costs and administrative effort. Batch jobs in BigQuery are designed to execute when resources are available, preventing interference with higher-priority workloads and optimizing resource usage without requiring active management. Based on the scenario described, batch processing offers a practical solution.
Question #25
You want to notify on-call engineers about a service degradation in production while minimizing development time.
What should you do?
What should you do?
- AUse Cloud Function to monitor resources and raise alerts.
- BUse Cloud Pub/Sub to monitor resources and raise alerts.
- CUse Stackdriver Error Reporting to capture errors and raise alerts.
- DUse Stackdriver Monitoring to monitor resources and raise alerts.
Correct Answer:
D
GPT
For notifying on-call engineers about production service degradation while minimizing development time, Stackdriver Monitoring is indeed the more fitting choice. It includes comprehensive monitoring tools that work out of the box, such as automated alerts based on preset or custom thresholds. This approach simplifies the process significantly, ensuring quick setup for monitoring and alerting without the hassle of excessive programming. Cloud Functions, while flexible, typically require more custom development to monitor specific resources effectively.
Question #26
You are writing a single-page web application with a user-interface that communicates with a third-party API for content using XMLHttpRequest. The data displayed on the UI by the API results is less critical than other data displayed on the same web page, so it is acceptable for some requests to not have the API data displayed in the UI. However, calls made to the API should not delay rendering of other parts of the user interface. You want your application to perform well when the API response is an error or a timeout.
What should you do?
What should you do?
- ASet the asynchronous option for your requests to the API to false and omit the widget displaying the API results when a timeout or error is encountered.
- BSet the asynchronous option for your request to the API to true and omit the widget displaying the API results when a timeout or error is encountered.
- CCatch timeout or error exceptions from the API call and keep trying with exponential backoff until the API response is successful.
- DCatch timeout or error exceptions from the API call and display the error response in the UI widget.
Correct Answer:
B
GPT
Upon reviewing the user comments and the options given in the question, it's evident that setting the XMLHttpRequest to asynchronous mode (option B) is the more appropriate approach. Employing asynchronous requests ensures that the UI remains responsive and other parts of the page do not get blocked while waiting for the third-party API to respond. This setup allows you to effectively handle API errors or timeouts by simply omitting the related widget, maintaining the performance and user experience of the rest of the page. The question stated that it was acceptable for some API data not to be displayed, aligning perfectly with this method.
Question #28
You are creating a Google Kubernetes Engine (GKE) cluster and run this command:
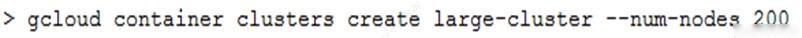
The command fails with the error:

You want to resolve the issue. What should you do?
The command fails with the error:
You want to resolve the issue. What should you do?
Question #29
You are parsing a log file that contains three columns: a timestamp, an account number (a string), and a transaction amount (a number). You want to calculate the sum of all transaction amounts for each unique account number efficiently.
Which data structure should you use?
Which data structure should you use?
- AA linked list
- BA hash table
- CA two-dimensional array
- DA comma-delimited string
Correct Answer:
B
B
GPT
Hash tables are your go-to for this task because they offer speedy access to your data. By using the account number as the key in a hash table, you can swiftly accumulate transaction amounts for each account. This method allows for rapid lookups and updates, which is much more efficient than alternatives like linked lists, arrays, or strings that could slow down the process with their less direct access methods. So, a hash table isn't just a choice here; it's a strategic move for efficiency.
Question #30
Your company has a BigQuery dataset named "Master" that keeps information about employee travel and expenses. This information is organized by employee department. That means employees should only be able to view information for their department. You want to apply a security framework to enforce this requirement with the minimum number of steps.
What should you do?
What should you do?
- ACreate a separate dataset for each department. Create a view with an appropriate WHERE clause to select records from a particular dataset for the specific department. Authorize this view to access records from your Master dataset. Give employees the permission to this department-specific dataset.
- BCreate a separate dataset for each department. Create a data pipeline for each department to copy appropriate information from the Master dataset to the specific dataset for the department. Give employees the permission to this department-specific dataset.
- CCreate a dataset named Master dataset. Create a separate view for each department in the Master dataset. Give employees access to the specific view for their department.
- DCreate a dataset named Master dataset. Create a separate table for each department in the Master dataset. Give employees access to the specific table for their department.
Correct Answer:
C
GPT
The correct approach in this scenario, considering efficiency and security, would be using BigQuery's authorization capabilities to set up dataset-level access. The idea is to divide the master dataset into separate department-specific datasets, then employ data pipelines to selectively copy necessary data from the master dataset to each respective departmental dataset. This ensures that each department only accesses its relevant data without interacting directly with the master dataset, which could contain sensitive or irrelevant information. This method, while slightly more resource-intensive in setup, upholds both data integrity and security by restricting access at the dataset level.
All Pages