Google Professional Data Engineer Exam Practice Questions (P. 1)
- Full Access (349 questions)
- One Year of Premium Access
- Access to one million comments
- Seamless ChatGPT Integration
- Ability to download PDF files
- Anki Flashcard files for revision
- No Captcha & No AdSense
- Advanced Exam Configuration
Question #1
Your company built a TensorFlow neutral-network model with a large number of neurons and layers. The model fits well for the training data. However, when tested against new data, it performs poorly. What method can you employ to address this?
- AThreading
- BSerialization
- CDropout Methods
- DDimensionality Reduction
Correct Answer:
C
Reference:
https://medium.com/mlreview/a-simple-deep-learning-model-for-stock-price-prediction-using-tensorflow-30505541d877

C
Reference:
https://medium.com/mlreview/a-simple-deep-learning-model-for-stock-price-prediction-using-tensorflow-30505541d877
Question #2
You are building a model to make clothing recommendations. You know a user's fashion preference is likely to change over time, so you build a data pipeline to stream new data back to the model as it becomes available. How should you use this data to train the model?
- AContinuously retrain the model on just the new data.
- BContinuously retrain the model on a combination of existing data and the new data.
- CTrain on the existing data while using the new data as your test set.
- DTrain on the new data while using the existing data as your test set.
Correct Answer:
B
B
 GPT
GPT
To keep your clothing recommendation model accurate and adaptive to changing fashion preferences, it's crucial to continuously retrain it on a blend of both existing data and new incoming data. This approach ensures that your model not only retains valuable insights from past data but also stays current with evolving trends, effectively balancing stability and responsiveness.
Question #3
You designed a database for patient records as a pilot project to cover a few hundred patients in three clinics. Your design used a single database table to represent all patients and their visits, and you used self-joins to generate reports. The server resource utilization was at 50%. Since then, the scope of the project has expanded. The database must now store 100 times more patient records. You can no longer run the reports, because they either take too long or they encounter errors with insufficient compute resources. How should you adjust the database design?
- AAdd capacity (memory and disk space) to the database server by the order of 200.
- BShard the tables into smaller ones based on date ranges, and only generate reports with prespecified date ranges.
- CNormalize the master patient-record table into the patient table and the visits table, and create other necessary tables to avoid self-join.
- DPartition the table into smaller tables, with one for each clinic. Run queries against the smaller table pairs, and use unions for consolidated reports.
Correct Answer:
C
C
GPT
Normalization in database design serves to enhance scalability and performance, making it a suitable strategy for handling large volumes of data such as your patient records. By splitting the database into distinct tables for patients and visits, you eliminate self-joins – which are notably inefficient for large datasets. This approach not only speeds up query processing but also ensures data integrity and simplifies management as the number of records grows. This solution will more effectively manage the increased scope of your project compared to simply adding capacity or reconfiguring tables.
Question #4
You create an important report for your large team in Google Data Studio 360. The report uses Google BigQuery as its data source. You notice that visualizations are not showing data that is less than 1 hour old. What should you do?
- ADisable caching by editing the report settings.
- BDisable caching in BigQuery by editing table details.
- CRefresh your browser tab showing the visualizations.
- DClear your browser history for the past hour then reload the tab showing the virtualizations.
Correct Answer:
A
Reference:
https://support.google.com/datastudio/answer/7020039?hl=en

A
Reference:
https://support.google.com/datastudio/answer/7020039?hl=en
Question #5
An external customer provides you with a daily dump of data from their database. The data flows into Google Cloud Storage GCS as comma-separated values
(CSV) files. You want to analyze this data in Google BigQuery, but the data could have rows that are formatted incorrectly or corrupted. How should you build this pipeline?
(CSV) files. You want to analyze this data in Google BigQuery, but the data could have rows that are formatted incorrectly or corrupted. How should you build this pipeline?
- AUse federated data sources, and check data in the SQL query.
- BEnable BigQuery monitoring in Google Stackdriver and create an alert.
- CImport the data into BigQuery using the gcloud CLI and set max_bad_records to 0.
- DRun a Google Cloud Dataflow batch pipeline to import the data into BigQuery, and push errors to another dead-letter table for analysis.
Correct Answer:
D
D
GPT
To handle the daily dump of CSV files with possibly corrupted or incorrectly formatted rows for analysis in Google BigQuery, the most efficient solution is to use a Google Cloud Dataflow batch pipeline. This method effectively segregates erroneous data by utilizing a dead-letter table, allowing for subsequent analysis without disrupting the main data flow. This approach ensures both the integrity and cleanliness of the data imported into BigQuery, facilitating accurate and reliable analytics.
Question #6
Your weather app queries a database every 15 minutes to get the current temperature. The frontend is powered by Google App Engine and server millions of users. How should you design the frontend to respond to a database failure?
- AIssue a command to restart the database servers.
- BRetry the query with exponential backoff, up to a cap of 15 minutes.
- CRetry the query every second until it comes back online to minimize staleness of data.
- DReduce the query frequency to once every hour until the database comes back online.
Correct Answer:
B
B
GPT
Using exponential backoff when handling database connection failures in Google App Engine applications is recommended as per Google's documentation. This method involves retrying the failed request with increasingly longer delays, which helps manage connectivity issues without overloading the database. This technique is particularly useful to avoid wasting database resources and helps in faster recovery of the services, ensuring applications remain functional and responsive even during database downtimes. Always ensure each retry is from the transaction's start if disruptions occur mid-transaction.
Question #7
You are creating a model to predict housing prices. Due to budget constraints, you must run it on a single resource-constrained virtual machine. Which learning algorithm should you use?
- ALinear regression
- BLogistic classification
- CRecurrent neural network
- DFeedforward neural network
Correct Answer:
A
A
GPT
Opting for linear regression is a smart move when you're working with a limited budget and simpler hardware. It's well-suited for predicting numerical values like housing prices and doesn't demand the heavy computational power that neural networks would. Linear regression can run efficiently on a basic CPU, making it a practical choice for your resource-constrained environment.
Question #8
You are building new real-time data warehouse for your company and will use Google BigQuery streaming inserts. There is no guarantee that data will only be sent in once but you do have a unique ID for each row of data and an event timestamp. You want to ensure that duplicates are not included while interactively querying data. Which query type should you use?
- AInclude ORDER BY DESK on timestamp column and LIMIT to 1.
- BUse GROUP BY on the unique ID column and timestamp column and SUM on the values.
- CUse the LAG window function with PARTITION by unique ID along with WHERE LAG IS NOT NULL.
- DUse the ROW_NUMBER window function with PARTITION by unique ID along with WHERE row equals 1.
Correct Answer:
D
D
GPT
The ROW_NUMBER window function, coupled with PARTITION BY on the unique ID, is the ideal approach for filtering out duplicates in your queries on a real-time data warehouse using BigQuery. It assigns a unique ranking to each row within each partition defined by the unique ID. By ordering these partitions by the event timestamp (ensuring to specify ORDER BY timestamp DESC within the OVER clause for clarity and precision) and filtering where the row number equals 1, the query successfully retrieves the most recent entry per unique ID, thereby eliminating duplicates effectively. This method is particularly useful when handling data susceptible to being inserted multiple times due to the nature of streaming inserts.
Question #9
Your company is using WILDCARD tables to query data across multiple tables with similar names. The SQL statement is currently failing with the following error:

Which table name will make the SQL statement work correctly?
Which table name will make the SQL statement work correctly?
- A'bigquery-public-data.noaa_gsod.gsod'
- Bbigquery-public-data.noaa_gsod.gsod*
- C'bigquery-public-data.noaa_gsod.gsod'*
- D'bigquery-public-data.noaa_gsod.gsod*`
Correct Answer:
D
Reference:
https://cloud.google.com/bigquery/docs/wildcard-tables
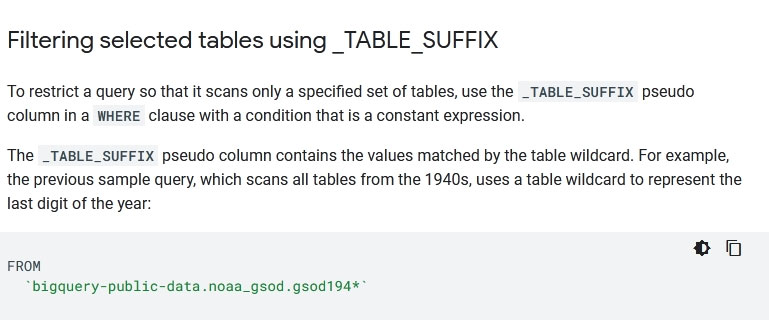
D
Reference:
https://cloud.google.com/bigquery/docs/wildcard-tables
Question #10
Your company is in a highly regulated industry. One of your requirements is to ensure individual users have access only to the minimum amount of information required to do their jobs. You want to enforce this requirement with Google BigQuery. Which three approaches can you take? (Choose three.)
- ADisable writes to certain tables.
- BRestrict access to tables by role.
- CEnsure that the data is encrypted at all times.
- DRestrict BigQuery API access to approved users.
- ESegregate data across multiple tables or databases.
- FUse Google Stackdriver Audit Logging to determine policy violations.
Correct Answer:
BDE
GPT
In a highly regulated environment, managing data access is crucial to ensure compliance and security. In BigQuery, restricting access to tables by role allows for the sculpting of access based on the minimum necessity principle, ensuring users only see what they need to perform their tasks. Additionally, limiting BigQuery API access to approved users through Cloud Identity and Access Management (IAM) provides a robust mechanism to prevent unauthorized data access. Implementing Google Stackdriver for audit logging complements these controls by enabling oversight and detection of any policy deviations, creating a comprehensive approach to data governance and security.
All Pages